
第二篇 计算机是如何学会下棋的(六)
清华大学计算机系 马少平
第六节:围棋中的强化学习方法
小明:艾博士,听说AlphaGo还采用了一种左右手互博的学习方法?
艾博士:左右手互博是一种通俗的说法,AlphaGo采用深度强化学习方法,通过自己与自己对弈提高自己的下棋水平。
小明:什么是深度强化学习呢?
艾博士:小明你一定看过动物表演吧?一群可爱的小狗在训狗师的带领下,会表演很多复杂的动作。这些小狗是如何学会表演的呢?训练起来并不容易。开始小狗可能什么也不知道,在训狗师的指挥下做动作,有些时候动作可能做对了,更多的时候可能做的不对。每当做对了一个动作时,训狗师就给小狗一些奖励,比如一些小狗喜欢吃的东西,做错了,可能小狗会被训斥,甚至挨打。慢慢地小狗就学会了在什么情况下做什么动作。训练过程中的小狗就是在进行强化学习。这里有两个主要的内容:一个是交互,即训狗师的手势和小狗的动作;一个是收益,得到了小狗喜欢的食物就是正的收益,而被训斥就是负的收益。对于一个聪明的小狗来说,它总是想获得更多的正的收益。开始小狗并不知道训狗师的手势是什么意思,它只是尝试做出一些动作,慢慢地通过是否获得奖赏或惩罚,小狗就明白了训狗师各种手势的不同含义,并做出正确的动作,学会了表演。图2.19给出了小狗训练示意图。

图2.18 动物表演
小明:那么如何将这一思想用到围棋中呢?
艾博士:在训练小狗的任务中,训狗师会发出指令,并根据小狗接收到指令后的动作给出奖赏或者惩罚,人的奖励或者惩罚,也就是小狗的收益是很及时的,小狗马上就知道刚才的动作是对还是错。这对小狗的学习是非常有利的。但是在围棋场景下,并没有一个人类围棋大师随时对计算机走的每一步棋做出评价,对于计算机来说,只能在一局棋结束之后才会知道哪一方获得了胜利,哪一方获得了失败。而一局棋是由很多步完成的,胜利的一方并不是每一步都走的正确,失败方也不是每一步都走的不好。这也正是围棋中的强化学习与训练小狗所不同的地方。
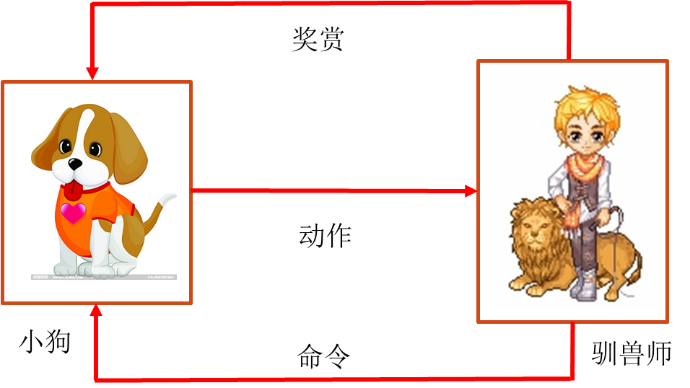
图2.19 小狗训练示意图
小明:那么如何解决这个问题呢?
艾博士:在围棋中,虽然不能保证胜利方每一步走的都是正确的,但是对于胜利一方来说,绝大多数行棋还是正确的,这样的假设应该是基本合理的。围棋中的强化学习就是利用这个假设,将自我对弈得到的棋谱作为训练样本,胜方的每步行棋都认为是正确的,应该加大其正确行棋的概率,而失败方的每步行棋都认为是不好的,应该减弱其相应的行棋概率。在这样的思想下,可以设计不同的强化学习方法。
小明:那么都有哪些深度强化学习方法呢?
艾博士:所谓的深度强化学习实际上就是用神经网络实现的强化学习方法。围棋中最常用的强化学习方法有三种,都是结合神经网络实现的,所以都属于深度强化学习方法。这里的关键因素就是如何确定训练样本、如何标记和定义什么样的损失函数。确定了这些内容之后,剩下的工作就跟普通神经网络的训练没有啥本质区别了,还是用BP算法对神经网络的权重进行调节、训练。简单地说,围棋中的强化学习方法,就是利用计算机自我对弈产生的数据,用对局的胜负作为标记,再定义适当的损失函数,利用BP算法进行训练的过程。
小明:计算机如何实现自我对弈呢?
艾博士:这个实现起来并不难,假设已经有了一个策略网络,这个策略网络可以是根据人类棋手的棋谱训练出来的,也可以是随机设定的权值得到的一个初始网络,那么对于任何一个棋局,策略网络都可以给出所有可落子点的概率值。我们把策略网络复制成两份,一个当作甲方,另一个当作乙方,每次选择概率值最大的可落子点作为行棋点,甲乙双方就可以实现对弈了。最后双方究竟谁是获胜者,可以用一个写好的程序来判定,至于具体的判定方法由于涉及到很多围棋知识,我们不再介绍了。在甲乙双方下棋过程中,记录下每一步棋局,并标记最终的胜方或者负方,这些具有胜负标记的棋局就可以作为样本用于强化学习了。
下面我们介绍围棋中三种常用的强化学习方法。
1、基于策略梯度的强化学习
艾博士:假设当前棋局为s,a是在自我对弈过程中甲方选择的走步, 是策略网络输出的在a处行棋的概率,并且假定最终甲方获得了胜利。由于在a处行棋最终获胜了,所以我们有理由认为在s棋局下在a处行棋是合理的,此时在a处行棋的理想概率 ta 应该为1,而其他可落子点的理想概率应该为0。经过训练后, pa 应该逼近 ta 才是合理的。为了达到这一目的,我们可以选择交叉熵损失函数,即:
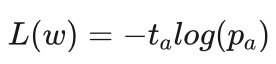
因为当用交叉熵损失函数进行优化时,刚好起到让 pa 尽可能逼近 ta 的目的。
由于甲方获胜时 ta 为1,所以实际上损失函数就是:
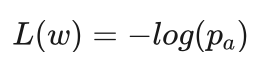
小明:对于甲方获负的情况如何处理呢?是不是 ta 为-1就可以了?
艾博士:确实这么处理的,但是对于交叉熵损失函数来说,理论上来说不能直接处理获负的情况,因为这里用的是概率,而概率不能是负数。这么处理的话需要一个合理的解释。
小明赶紧问:怎么解释呢?
艾博士:在获胜的情况下,BP算法根据梯度的大小和方向通过调节神经网络的权重达到提高 pa 值的目的。在获负的情况下,说明在a处不是一个好的行棋点,应该减小在a处下棋的概率,也就是应该调整权重使得策略网络在a出的输出值 pa下降。我们可以认为对于获胜或者获负,对权重调整的大小是一样的,只是方向相反。比如对于获胜的情况,如果对于某个权重 wi ,BP算法是加大了 wi 的值,则同样条件下,对于获负的情况就应该是减少 wi 的值,且加大或减少的大小是一样的。反之也一样。在这样的假设下,对于获负的样本,我们直接令 ta 为-1就可以了,因为对于交叉熵损失函数来说,这样处理后的梯度方向刚好与获胜样本的梯度是相反的,而梯度的绝对值又是一样大的,刚好符合我们希望的结果。
小明:这么一解释就比较合理了。
艾博士:我们总结一下基于策略梯度的强化学习方法的学习过程:
(1)以策略网络为基础构建一个围棋系统进行多次自我对弈,记录对弈过程中出现的全部棋局,并根据每局棋的胜负做出标记,获胜标记为1,获负标记为-1。这些带标记的棋局作为训练样本;
(2)以交叉熵作为损失函数,用BP算法调节策略网络的权重,改善其输出概率的性能;
(3)当完成一轮训练之后,以新的策略网络代替当前策略网络,重复以上过程,直到训练结束。
艾博士强调说:这里有两点需要注意,一是在强化学习过程中,每个样本只使用一次,因为强化学习的样本是自我对弈产生的,如同前面说过的一样,对于获胜者来说,并不是他的每一步行棋都是正确的,可能含有很大的噪声,尤其是在学习的早期阶段,当策略网络性能比较差的时候更是如此。所以为了防止错误的样本被强化,每个样本只使用一次。由于样本来自自我对弈,可以产生足够多的样本,所以也不存在样本不够的问题,需要多少产生多少就可以了。这与非强化学习中用人类棋手棋谱训练时样本被多次反复使用有所不同,因为人类棋谱质量是比较可靠的,而且棋谱也是有限的,不可能随意增加。二是基于策略梯度的强化学习方法学习的是在每个可落子点行棋的获胜概率,因为样本标记就是获胜或者获负。这与从人类棋谱中学习策略网络也有所区别,后者学习的是在某个可落子点行棋的概率。虽然概念上有所不同,但是都可以作为策略网络使用。
2、基于价值评估的强化学习
艾博士:小明,看过围棋比赛直播吗?
小明:艾博士,我会点围棋,经常看电视传播,很喜欢听讲解员的讲解。
艾博士:讲解员在讲解时经常会说这步棋下在这里比较好、下在那里不太好、这是一步好棋等,或者说目前的局势对黑方有利或者对白方有利、双方局面相差不多等。类似的评论信息其实就是对围棋局面的评估。基于价值评估的强化学习就是想训练一个称作行动-价值网络的神经网络,对每一个可能的走步做出评估。
行动-价值网络如图2.20所示,有两个输入,一个输入为当前棋局,一个输入为可能的走步,输出是一个-1、1之间的数值,表示这步棋之后所形成的棋局的估值,也就是收益。大于0表示对我方有利,小于0表示对对方有利。

图2.20 行动-价值网络

图2.21 行动-价值网络示意图
训练样本同样来自于自我博弈,当前棋局以及下一步的行棋点作为一个样本,这盘棋的最终胜负作为样本的标记,获胜标记为1,获负标记为-1,这也是行动-价值网络的学习目标。行动-价值网络的输出为介于-1和1之间的一个数值,该数值是对这盘棋最终胜负情况的一个预测。所以行动-价值网络的输出应该尽可能接近1或者-1,为此我们可以选择误差的平方作为损失函数,也就是棋局最终的胜负值与行动-价值网络的输出值之差的平方作为损失函数。即:
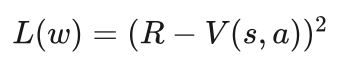
其中R为胜负标记,V(s,a)为当前棋局s下,在a处落子时估值网络的输出。
小明:艾博士,经您的讲解,我大概明白了基于价值评估的强化学习方法,通过一个神经网络实现行动-价值网络,并用强化学习方法训练得到该网络。那么,这个行动-价值网络大概是个什么样的呢?
艾博士:图2.21给出了行动-价值网络示意图。对于当前棋局输入部分,先通过几个卷积层、全连接层处理后,再与当前落子点输入部分“汇合”,再经过几个全连接层,最后有一个单个神经元的输出层,经过tanh激活函数将输出转换到-1、1之间,这也是我们所希望的输出范围。
小明:在行动-价值网络中为什么两个输入是先分开处理,最后再合并呢?
艾博士:图2.21中虚线部分可以认为是照搬策略网络过来的,在策略网络中为了得到每个行棋点的行棋概率,需要对当前棋局做详细的分析。在行动-价值网络中,为了预测局势估值,有理由认为在策略网络中用到的这些分析也是必须的,所以在对当前局势进行一定处理之后,再与当前选择的行棋点相结合,对局势估值进行预测。图2.21给出的行动-价值网络就是在这样的想法下给出的示意图,当然也不排除有其他的设计思想,并没有定论一定需要这样的设计。
小明:我明白了,原来是这样的设计思想。
3、基于演员-评价方法的强化学习
艾博士:小明你会下围棋,每次下完棋后是否要进行复盘呢?
小明:在围棋班学习的时候,老师每次都要求我们进行复盘,进行总结。尤其是跟老师下棋的时候,老师会非常认真地对我们的每一步走法进行评价,这对我们学习围棋非常重要。
艾博士:有些读者可能还不知道什么叫复盘,小明你给解释一下?
小明:所谓复盘就是对刚下完的一盘棋一步一步再复现一次,分析哪一步走的好,哪一步走的不好,尤其是分析那些具有决定作用的行棋,比如走的特别好的、确定了优势的走步,或者走的不好的、从此转向劣势的走步,对这些行棋做重点分析。
艾博士:这里特别强调那些扭转乾坤或者被扭转乾坤的行棋。这就好比在篮球比赛中,在比分已经领先比较多的情况下,投进几个3分球固然精彩,但是对于胜败所起的作用并不大,但是如果在落后的情况下,比如在最后几秒钟还落后1、2分的情况下,投进一个压哨的3分球,那绝对就是扭转乾坤之举,直接关系到了最后的胜败。基于演员-评价方法的强化学习,就是想体现出这种想法,重点学习那些决定成败的走法。
小明:为什么叫做演员-评价方法呢?
艾博士:这是一种类比,就好比一个演员在学习表演,一位老师在指导他。每次演员表演完后,老师对他的表演进行评价,指出做的好的地方和做的不好的地方,演员再改进,一直重复下去,演员逐渐就提高了表演水平。跟老师在围棋复盘时对你进行指导是一样的。
小明:原来是这样,我明白了,挺形象的一个名称。
艾博士:为了实现对重点走步的评价,我们引进一个收益增量的概念。
设当前棋局为s,其预期收益为V(s),在a处走了一步棋后的收益为Q(s,a),二者的取值范围均在-1和1之间。则在a处行棋之后的收益增量A为:
A=Q(s,a)-V(s)
由于V(s)、Q(s,a)的取值范围都在-1、1之间,所以A的取值范围在-2、2之间。
小明:如何理解这个收益增量呢?
艾博士:可以这样来理解收益增量,假设当前棋局s已经对甲方很有利了,也就是V(s)值很大已经接近于1了,那么当在a处行棋之后,局面仍然对甲方有利,那么在a处行棋的收益增量并不是很大,就如同在篮球比赛中处于绝对领先的情况下,投进了一个三分球一样。但是如果在a处行棋之后,本来处于优势的甲方变成劣势了,那么在a处行棋的收益增量就是负的,说明走了一个败招。反之,如果当前局势对甲方是不利的,也就是V(s)值是负的,如果这时在a处行棋之后,局势对甲方有利了,那么在a处的行棋就绝对是一步扭转乾坤的棋,获得比较大的收益增量。
小明:我明白了收益增量的含义,就是对关键棋的分析。收益增量在0左右时,说明下了一步比较正常的棋,在a处行棋前后双方局势没有大的变化。收益增量接近2时,则是下了一步妙招,而收益增量接近-2时,则表示走了一个大败着。这两种情况均表示双方的局面发生了大逆转。
艾博士:小明越来越会思考了,你总结的非常到位。接下来的问题是,如何计算V(s)、Q(s,a)这两个量。
小明:是啊,怎么计算呢?
艾博士:V(s)的值我们可以用一个神经网络进行估计,Q(s,a)的值可以用一盘棋最终的收益R代替,获胜时R值为1,获负时R值为-1。这样实际应用时收益增量的计算公式如下:
A=R-V(s)
这里的收益增量A就相当于教师对演员的评价。
小明:收益增量A相当于教师的评价,那么谁是演员呢?
艾博士:小明提了一个好问题。我们用强化学习训练的还是策略网络,策略网络就相当于是演员。我们希望利用“教师”信息A辅助训练策略网络。实际上,基于演员-评价方法的强化学习相当于是我们前面讲过的基于策略梯度的强化学习和基于价值评估方法的强化学习两种方法的融合。
小明:是怎么将两种方法融合在一起的呢?
艾博士:在基于演员-评价方法的强化学习中,采用了一个具有两个输出的神经网络,分别作为策略网络的输出和收益V(s),如图2.22所示。该网络称作演员-评价网络。
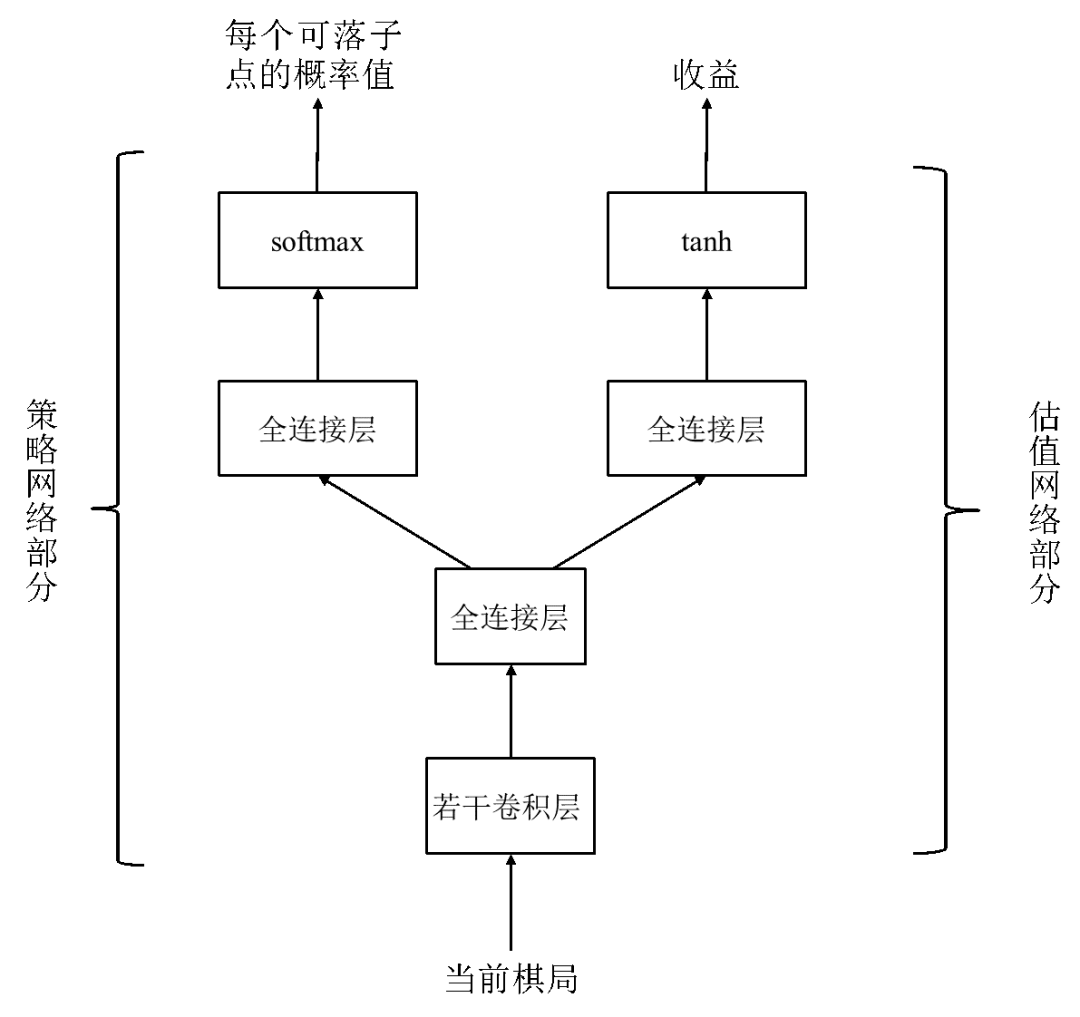
图2.22 演员-评价网络示意图
艾博士:在进行强化学习的时候,样本同样来自于自我对弈产生的棋谱,每一个棋局标记一个这局棋的胜负收益,即1或者-1,同时还有一个通过A=R-V(s)计算得到的收益增量,其中R就是这局棋的胜负收益,而V(s)就是图2.22所示的演员-评价网络右边的输出值,也就是预测的当前棋局的收益。
小明:对于这种具有两个不同的输出的网络,损失函数是怎么定义的呢?
艾博士:两个输出分别定义损失函数,然后再通过加权的形式合并在一起。对于演员-评价网络来说,相当于是策略网络和估值网络两个网络的组合。对于其中的策略网络部分来说,损失函数选取类似于前面讲过的基于策略梯度的强化学习方法中的交叉熵损失函数,只是将损失函数中的胜负值用这里给出的收益增量代替,这也是为了体现加强对重点走法的学习,因为收益增量可以评价每个走法的重要程度。具体如下:
设s是当前棋局,pa 是策略函数部分给出的在a处下棋的概率,A是收益增量,则这部分的损失函数为:
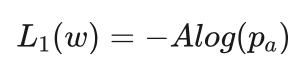
对于估值网络部分来说,输出V(s)就是对胜负值R的预测,这种情况下一般会采用误差的平方损失函数,即:
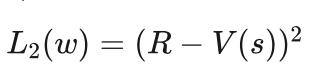
两个损失函数合并在一起作为演员-评价网络总的损失函数:
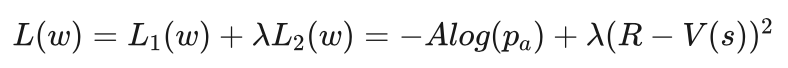
其中λ为调整参数,在两个损失函数之间进行调节
。
通过图2.22所示的神经网络,以及上述的联合损失函数,基于演员-评价的强化学习方法,同时学习策略网络和估值网络,并通过将收益增量引入到损失函数中,实现对重要走法的学习。
艾博士总结说:上面我们介绍了三种典型的用于计算机围棋的强化学习方法,这三种方法总体上来说大同小异,都是通过自我博弈实现自我学习,逐步提高下棋水平。三种方法则重点不同,通过设计不同的损失函数以达到不同的目的。对于基于策略梯度的强化学习方法来说,通过每局棋的胜负指导学习,学习到的是每个落子点获胜的概率,在使用时选取获胜概率最大的可落子点作为行棋点。对于基于价值评估的强化学习方法来说,虽然也是通过每局棋的胜负指导学习,但学习到的是在每个落子点的胜负收益,在使用时选取收益最大的落子点作为行棋点。而对于基于演员-评价的强化学习方法来说,强调的是重要行棋点的学习,也就是一局棋中一些重要走法的学习,通过收益增量对走法的重要性进行评价,最终策略网络学习到的是每个落子点获得最大收益增量的概率。
回想一下AlphaGo中的策略网络,是利用人类棋谱作为样本进行学习的,其习得的是人类棋手在该点行棋的概率。所以,虽然最终训练的都是策略网络,但是其具体含义是不同的,体现了不同的策略。
小明读书笔记
强化学习是通过自我产生数据进行学习的一种方法,深度强化学习就是采用神经网络实现的强化学习方法。
强化学习的重点是如何利用自我产生的数据设计训练样本,以及如何根据训练样本包含的相关信息设计损失函数。当样本和损失函数确定后,深度强化学习和普通的深度学习,也就是神经网络训练并没有什么本质区别。不同的损失函数体现了不同的训练思想。
基于策略梯度的强化学习方法,利用结果的胜负作为标记,采用交叉熵损失函数进行学习,训练的是在每个落子点获胜的概率。采用了一个小技巧处理失败情况下的样本,当获胜时增加相应位置行棋的概率,而当失败时则减少相应位置的行棋概率。这种方法只能应用于交叉熵损失函数这种情况,对其他损失函数可能并不合适。
基于价值评估的强化学习方法,学习的是每个落子点的收益,它以当前棋局和一个落子点作为输入,输出在该落子点行棋后的收益预测。收益是对该局棋胜负的预测,用误差的平方作为损失函数进行学习。
基于演员-评价的强化学习方法,引入了收益增量的概念,该概念是对一步棋重要性的评价,重点学习那些直接关乎胜负的走法。该方法将策略网络和估值网络融合为一个网络一起学习,具有两个输出,分别对应于策略网络的输出和估值网络的输出。在策略网络部分利用收益增量作为标记,使用类似于交叉熵函数的损失函数。在估值网络部分,还是用误差的平方作为损失函数。
在强化学习中,由于样本是通过自我对弈产生的,往往噪声比较大,所以在训练时一般每个样本只使用一次,而不像一般的深度学习中样本被反复使用,好在样本是自我产生的,可以产生足够多的样本满足需要。
未完待续