
第三篇 计算机是如何找到最优路径的(八)
清华大学计算机系 马少平
第八节:拼音输入法问题
艾博士:就如同前面曾经提到过的,最短路径问题不只是单纯的可以求解狭义的路径问题,很多问题可以转化为最短路径问题。比如拼音输入法问题。
小明:什么是拼音输入法问题?拼音输入法与最短路径问题又是什么关系?
艾博士:所谓拼音输入法问题,就是输入一个拼音串如何转换为对应的汉字问题,现在很多人用的输入法就属于这样的问题。该问题实际上可以转化为求最短路径问题。
小明:拼音输入法还跟最短路径有关?听起来有些神奇,请艾博士快给讲讲。
艾博士:小明请你看看下面一串拼音应该对应什么汉语句子?
ji qi xue xi ji qi ying yong
小明边看边思考,想了一会说:应该是“机器学习及其应用”。
艾博士:小明反应真快。
在这串拼音中,每个拼音对应着很多汉字,图3.33给出了每个拼音对应的部分汉字。

图3.33 每个拼音对应多个汉字示意图
艾博士指着图对小明说:你看,拼音“ji”可以对应“及、计、机”等汉字,拼音“qi”可以对应“期、器、其”等汉字……从每个拼音对应的汉字中取出一个汉字,就可能对应着一句汉语句子,比如小明说的“机器学习及其应用”,但是也有可能是“机器学习机器应用”,或者“及其学习及其应用”等。
说到这里,艾博士反问小明:这串拼音可以对应很多个句子,你为什么只选择“机器学习及其应用”这句话呢?
小明想了想说:因为感觉这句话比较通顺,是一句话,而其他的似乎不太通顺。比如您提到的“及其学习及其应用”就不通顺,让人看不明白在说什么。“机器学习机器应用”这句话看起来还有些通顺,但是不如“机器学习及其应用”这句话更像正常的句子。至于其他的,就更不像句子了。
艾博士:小明回答的很好。虽然这串拼音可以组成很多种不同的句子,但是绝大多数一看就不像句子,比如我们取图3.33中的第一行汉字“及期学系及期应勇”,一看就不是句子。我们人类很聪明,很快就可以挑选出正确的句子来,关键是我们有多年的阅读经验,很快就可以把明显不是句子的淘汰掉,选择出正确的句子。
事实上,汉语约有400个左右不带声调的音,常用汉字也大概有4000个左右,平均一个音对应10个汉字。而据统计,汉语句子的平均长度约为11个汉字。如果按照每个拼音对应10个汉字的平均值计算,一个具有11个拼音的拼音串,对应着10^11 个可能的句子。这是什么概念呢?假设1毫秒生成一个句子的话,大约需要3年时间才能把这些句子全部生成出来。
小明听到这里忍不住惊呼到:竟然需要这么长的时间!
艾博士:所以说,拼音输入法问题是一个比较复杂的问题。这里涉及两个问题:一个问题是如何判断一个句子是否通顺,一个问题是如何快速地将最通顺的这个句子找出来。
小明:是啊,平时每天都在使用拼音输入法,早已习以为常,没想到竟然会这么复杂。
艾博士:为了求解拼音输入法问题,需要将该问题转化为一个计算机可以求解的问题,然后再利用已有的算法进行求解。
小明:应该怎么转换呢?
艾博士:在讲解如何求解输入法问题之前,我们先简要介绍一下贝叶斯公式,因为在讲解输入法问题时,需要用到贝叶斯公式。
贝叶斯公式用来描述两个条件概率之间的关系。如图3.34所示,左边的圆表示“阴天”,右边的圆表示“湿度大”,两圆重叠的部分表示“阴天又湿度大”。如果“阴天”的概率用P(阴天)表示,“湿度大”的概率用P(湿度大)表示,“阴天的条件下湿度大”的概率用P(湿度大|阴天)表示,“湿度大的条件下阴天”的概率用P(阴天|湿度大),“阴天又湿度大”的概率用P(阴天又湿度大)表示,则“阴天又湿度大”的概率可以表示为:
P(阴天又湿度大)=P(湿度大|阴天)·P(阴天)
小明:如何理解这个公式呢?
艾博士:这个公式可以这样理解,阴天的情况下,可能湿度大,也可能湿度不大,所以在阴天的情况下,有个湿度是否大的概率,即P(湿度大|阴天)。但是阴天也是有时发生有时不发生的,也存在概率问题,所以阴天又湿度大的概率就是阴天的情况下湿度大的概率乘以阴天的概率。
小明:我明白了。先考虑阴天情况下湿度大的概率,再考虑阴天的概率,二者相乘就是阴天又湿度大的概率。
艾博士:这是从“阴天”的角度求解“阴天又湿度大”的概率。同理,也可以从“湿度大”的角度求“阴天又湿度大”的概率,则“阴天又湿度大”的概率可以表示为:
P(阴天又湿度大)=P(阴天|湿度大)·P(湿度大)
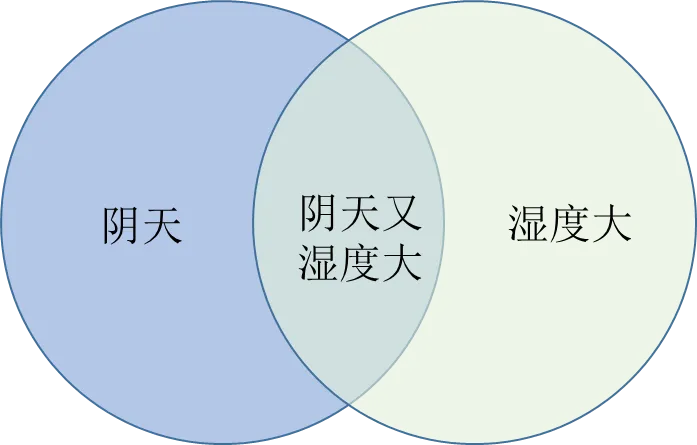
图3.34 贝叶斯公式示意图
两个公式是对称的,从不同角度求解了“阴天又湿度大”的概率。两个概率应该是相等的,所以有:
P(湿度大|阴天)·P(阴天) = P(阴天|湿度大)·P(湿度大)
整理有:
P(湿度大|阴天) = P(阴天|湿度大)·P(湿度大)/P(阴天)
扩展到一般情况,我们用A表示“阴天”,B表示“湿度大”,则上述公式可以表示为:
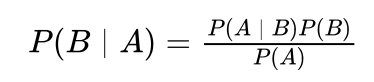
这就是贝叶斯公式。如果想计算概率P(B│A),但又不方便计算时,可以通过该公式转换为 [P(A|B)P(B)]/P(A) 计算,如果这个公式更容易计算的话。
小明:贝叶斯公式跟拼音输入法问题有什么关系呢?
艾博士:我们的目的就是想利用贝叶斯公式将拼音输入法问题转换为我们熟悉的最短路径问题,通过求解最短路径问题,确定拼音串对应的汉语句子。
小明:我一时还想不明白二者之间具有什么关系。
艾博士:小明你别着急,我们慢慢讲解你就明白了。
我们假设用字母O表示给定的拼音串,其可能对应的汉语句子为S。如何判断S是否通顺呢?我们计算给定O时对应句子是S的概率P(S|O)。如果这个概率计算是合理的,则有理由相信概率大的句子其成为句子的可能性就越大。
所以,拼音输入法问题就是用概率P(S|O)的大小作为评判一个句子是否通顺的根据,从拼音串O对应的所有可能句子中,找出概率P(S|O)最大的句子,作为拼音串O所对应的句子。
小明不明白地问:可是如何计算概率P(S|O)呢?我没有一点思路。
艾博士:直接计算确实有困难,我们可以利用贝叶斯公式做一个转换。按照贝叶斯公式:
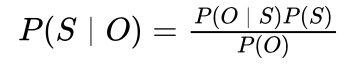
公式中P(S)表示S是一个句子的概率,P(O)表示这串拼音出现的概率,P(O│S)表示句子S对应的拼音串是O的概率。
每个拼音对应的汉字确定后,拼音串O对应的可能句子也是确定的,虽然可能会很多。我们的目的是从众多的这些句子中选出概率最大的句子,并不关心具体概率是多少,只要该句子的概率最大即可。
由于当前讨论的是给定拼音串所对应的句子,拼音串O是给定好的,所有句子都是针对该拼音串说的,所以对这些不同的句子来说,概率P(O)的值是固定的常量,因此在求概率最大的句子时可以不考虑P(O)的大小,概率 P(S|O)+[P(O|S)P(S)]/P(O) 最大对应的句子S,与P(O│S)P(S)最大对应的句子是同一个句子。
在汉语句子中,虽然会有多音字,但是一旦句子给定后,其对应的拼音串基本也是固定的,因为绝大多数多音字在句子中的读音是确定的。比如:
“反省一下省下来的钱干什么”
虽然“省”字是个多音字,有“sheng”和“xing”两个读音,但在上述句子中,第一个“省”读“xing”、第二个“省”读“sheng”是确定的。所以对于句子S所对应的拼音串是O的概率P(O│S)可以认为约等于1,也是个常量。
这样一来,P(S│O)最大对应的句子S,与P(S)最大对应的句子又是同一个句子了。所以我们只要求概率P(S)最大对应的句子就可以了,只是这些句子被限制在是拼音串O所限制的范围内。
小明:P(S)表示的是S成为句子的概率,这个概率怎么计算呢?
艾博士:要计算S成为句子的概率P(S),这就要用到统计语言模型了。
设一个含有N个汉字的句子为:
w1w2...wn
其中 wi 表示汉字。
在统计语言模型中,假定句子中第i个汉字的出现与该句子中前面i-1个汉字的出现有关,一个句子的概率则是该句子中所有汉字出现概率的乘积,其计算公式由下式给出:
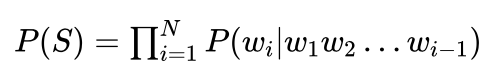
其中 P(wi|w1w2...wi-1) 表示当句子中前i-1个汉字为 w1w2...wi-1 时,第i个汉字为 wi 的概率,符号“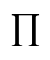 ”表示“连乘”,也就是每个汉字出现在句子中的概率连乘在一起就是句子的概率。
”表示“连乘”,也就是每个汉字出现在句子中的概率连乘在一起就是句子的概率。
当句子比较长时,这样的语言模型参数会非常多,为了减少模型的参数,一般会假定句子中一个汉字的出现只与其前面n-1个汉字有关,称作n元语言模型。这样句子概率的计算可以修改为:
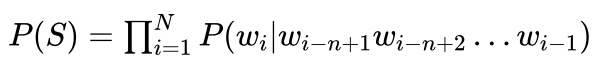
当n=2时我们可以得到二元语言模型:
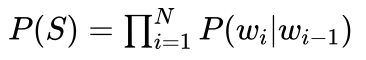
为了简化计算,我们下面将采用二元语言模型计算一个句子S的概率。
小明:艾博士,我明白了如何用统计语言模型计算一个句子的概率,但是如何得到概率 P(wi|wi-1) 呢?
艾博士:这个概率值可以通过统计的办法获得。
首先我们从网络上抓取大量的文本信息作为语料库。然后根据语料库统计计算获得概率值 P(wi|wi-1) 。比如,“清”后面出现“华”的概率P(华|清):

采用类似的方法,对于任何两个汉字,都可以计算出当一个汉字出现时另一个汉字出现的概率。事先计算好这些概率值存储起来,等待需要时可以随时调用使用。
小明:即便是只考虑常用汉字,也大概有4000多个,任何两个汉字都需要统计计算并存贮保存,是不是计算量、存储量都很大啊?
艾博士:事实上在实际的句子中,并不是任何两个汉字都会前后同时出现的,只有少量的汉字具有这种同现关系,所以大量的概率值都是0,非0概率所占比例并不大。
不过虽然比例并不大,但是由于基数大,非0概率的量还是不少的。
小明:好的,我明白了。至此我们知道了如何计算一个句子的概率,但是如何用到拼音输入法问题上,解决拼音输入法问题呢?
艾博士:有了语言模型之后,输入法问题就变成了从拼音串对应的可能汉语句子中,找出概率最大的句子问题了。也就是求:
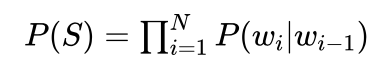
最大时对应的句子S,而S的候选是拼音串所对应的所有可能的句子。
小明:把所有可能的句子都生成出来,一个一个计算每个句子的概率吗?
艾博士:前面已经说过,由于对应的可能句子太多,是不可能通过产生所有句子的办法获得最大概率的句子的。
小明想起来了:前面是分析过,按照平均句子长度为11个汉字,每个拼音对应10个汉字的平均值计算,一个具有11个拼音的拼音串,对应着 10^11 个可能的句子。假设1毫秒生成一个句子的话,大约需要3年时间才能把这些句子生成出来。
艾博士:这时就需要算法的力量了。
为了计算方便,我对下式两边取对数:
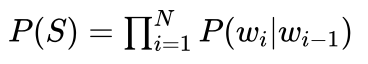
有:
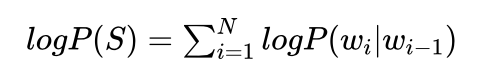
这样一方面可以将乘法变成加法,另一方面P(S)最大对应的句子S与log(P(S))最大对应的句子S是一致的,所以求log(P(S))最大对应的句子就可以了。
另外,求log(P(S))最大与求-log(P(S))最小是等价的,所以问题就又变成了求-log(P(S))最小对应的句子S。也就是求下式:
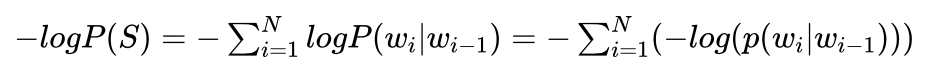
最小时对应的句子S。
小明不太解地问:这么变换的目的是什么呢?
艾博士:不要着急,很快你就可以看到为什么做这些变换了,总的来说,就是想把拼音输入法问题变换为求最短路径问题。
前面说过,拼音串中每个拼音对应若干个汉字,我们将这些汉字称作候选汉字。如果将每个候选汉字看做是一个节点,前后两列间的候选汉字从左到右做一个连接,用 -log(P(wi|wi-1))当作连接间的代价,其中wi-1 、wi 为拼音串对应的一个可能句子中前后两个相邻的汉字。这样所有候选汉字就可以组成一个篱笆型有向图,如图3.35所示给出了一个这样的例子,其对应的拼音串就是我们前面提到过的“ji qi xue xi ji qi ying yong”,其中我们在前后增加了一个初始节点和目标节点。图中从初始节点到目标节点的一条路径,就对应了拼音串对应的可能句子,而 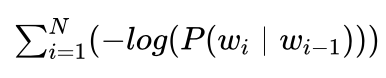 就是该路径的总代价。
就是该路径的总代价。
根据前面的分析,拼音输入法问题就是求 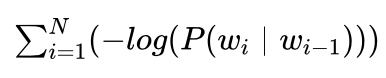 最小时所对应的句子,也就是图3.35所示的最优路径。
最小时所对应的句子,也就是图3.35所示的最优路径。
这样一来,我们就将拼音输入法问题转化为了求解篱笆型有向图最优路径问题,可以采用前面介绍过的Viterbi算法求解。
小明:这样我就理解了为什么前面做那些转换了,经过这样的转换后,拼音输入法问题就纯粹是一个最优路径求解问题了。现在有很多拼音输入法,都是采用这样的方法实现的吗?
艾博士:现在大家使用的拼音输入法都是采用这样的原理实现的,只是我们为了简化问题,假定了拼音之间具有空格,省略了其中的拼音分词(字)问题。另外,我们这里采用的是关于字的二元语法,也就是只考虑一句话中两个相邻汉字之间的概率关系,也可以采用关于字的三元语法,或者更多元的语法,效果会更好,当然同时也会加大计算量。甚至可以考虑关于词的二元语法,或者是词的三元语法,一般来说,采用词的语言模型的效果要好于采用字的语言模型的效果,但由于词的数量要远远多于字的数量,其计算量、存储量也会更大,求解起来也会更加复杂。无论具体是几元语法,采用字模型还是词模型,基本原理都是一样的。
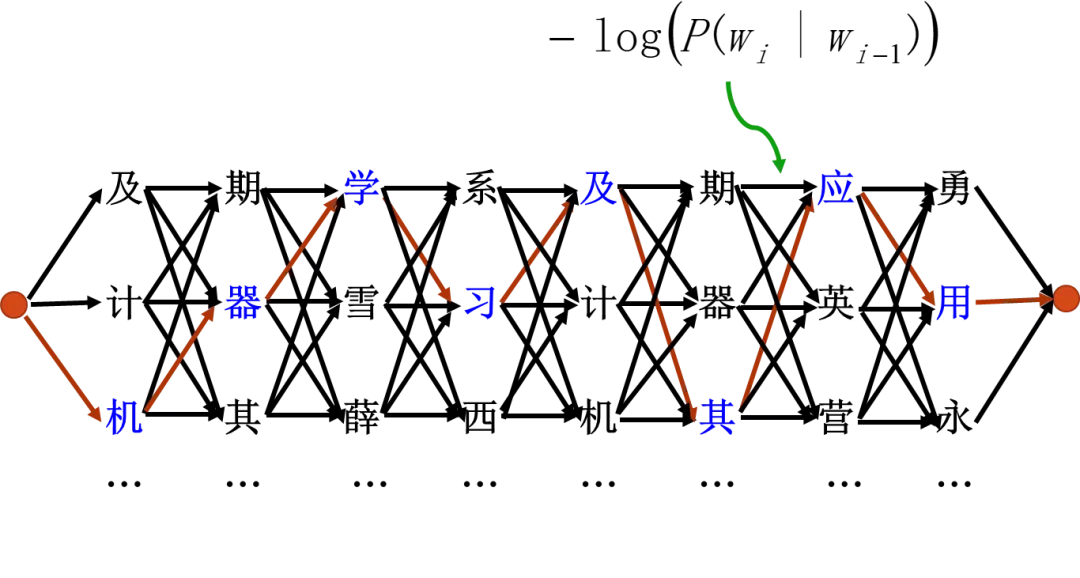
图3.35 候选汉字组成的篱笆型有向图
小明:这真是一个很好的应用例子,初看起来拼音输入法跟最短路径问题没啥关系,通过一定的变换后,二者其实是同样的问题,利用已有的方法就可以求解了。
艾博士:在用人工智能求解具体问题时往往采用的都是这种方法,转换到一个已知问题后,再采用已有的方法求解。像AlphaGo就是把下围棋问题转化到了一个分类问题。围棋盘上的任何一点都可以看做是一个类别,在当前局势下在哪里下棋,可以认为是将该棋局分类到哪个类别。AlphaGo利用深度学习实现了这一点,但是AlphaGo又有发展,针对下棋问题的特点,将该“分类”问题融入到蒙特卡洛树搜索中,有效提升了下围棋的性能。所以在学习人工智能方法时,要学会触类旁通、举一反三地求解问题。
小明读书笔记
对于给定一个拼音串如何确定其对应的汉语句子?这就是拼音输入法问题。由于每个拼音对应多个汉字,所以一个拼音串可能对应的汉语句子会非常多。
在汉语中约有400左右不带声调的音,常用汉字也大概有4000个左右,平均一个音对应10个汉字。而据统计,汉语句子的平均长度为11个汉字。如果按照每个拼音对应10个汉字的平均值计算,一个具有11个拼音的拼音串,对应着 10^11 个可能的句子。这是什么概念呢?假设1毫秒生成一个句子的话,大约需要3年时间才能把这些句子生成出来。如何从这么多可能的汉语句子中找出拼音串最可能对应的句子,是一个比较困难的问题,需要解决两个问题:一是如何评价一个句子是否通顺,二是如何从这么多句子中快速找出最通顺的句子,也就是最像汉语句子的句子。
通过贝叶斯公式,我们可以将拼音输入法问题转化为最短路径求解问题。如果任何两个汉字之间的连接概率用 P(wi|wi-1) 表示的话,其中wi 表示给定拼音串对应的一个可能句子中的的第i个汉字,则拼音输入法问题可以转化为求解下式最小问题:
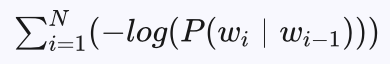
如果句子中两个汉字之间的代价表示为 -log(P(wi|wi-1)),则拼音输入法问题实际上就是求由给定拼音串中拼音对应的所有候选汉字组成的篱笆型有向图的最短路径问题,每个句子的路径长度由上式给出,通过Viterbi算法就可以得到该问题的最优解,从而得到给定拼音串最对应的汉语句子,也就是概率最大的句子。
其中用到的任意两个汉字之间的连接概率,可以通过语料库统计获得。
这里用到的是以字为单位的二元语言模型,也可以采用以字为单位的三元语言模型,或者是以词为单位的二元语言模型,甚至三元语言模型。
未完待续