
第三篇 计算机是如何找到最优路径的(四)上
清华大学计算机系 马少平
第四节:启发式搜索
1、A算法
艾博士:迪杰斯特拉算法具有很好的性质,可以找到最小代价的路径。但是该算法也存在明显的不足。小明你想想看,有什么不足?
小明仔细看着图3.10所示的搜索图思考了一下说:艾博士,我一时还说不出来有什么不足。
艾博士启发小明说:你把图3.10所示的搜索图中节点的扩展次序标注到图3.9所示的状态连接图上,是否会发现点什么问题?
小明思考了一下,按照艾博士的要求在状态连接图上的标识出节点的扩展次序,如图3.11所示。
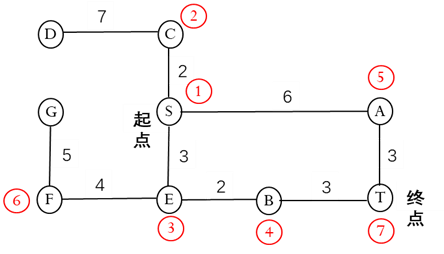
图3.11 标注了扩展次序的状态连接图
然后,小明看着图思考起来。不一会小明就发现了问题,对艾博士说:我知道了迪杰斯特拉算法存在的不足了,我试着说一下,请艾博士看看是否正确。
在图3.11中,状态C是远离目标状态的,却第二个就被扩展,比距离目标更近且方向也正确的E、B先扩展。而状态F不仅远离目标状态,方向也是完全相反的,却也要尝试进行扩展。这是不是就是该算法存在的问题?
艾博士高兴地说:小明你分析的非常正确,这正是该算法存在的不足。算法只利用了一个节点的g值,优先扩展g值小的节点,而完全没有考虑这个节点是否距离目标更近。这样会造成很多不必要的节点扩展,严重降低算法的求解效率。
小明忍不住问艾博士:那么怎么克服这一不足呢?
艾博士:一种解决办法就是在选择待扩展节点时,不只是考虑该节点的g值,同时还要考虑该节点到目标节点的距离。假设我们用h(n)表示节点n到目标节点的距离,那么:
f(n) = g(n) + h(n)
就反应了从初始节点S经过节点n到达目标节点T的路径距离,也就是这条路径的代价。比如在前面的例子中,由于C和F都是远离目标状态的,它们的h值就会比较大,从而导致f值比较大,就有可能避免对这两个节点的扩展,从而提高了算法的效率。
听到这里,小明很高兴地说:对啊,这样的话就可以提高搜索效率了。
刚说到这里,小明刚刚还在微笑的面孔突然又凝固起来:可是,一个节点的h值怎么计算呢?我们如何知道一个节点到达目标的距离呢?
艾博士说:你的疑虑是对的,一个节点的h值确实无法事先知道,但是我们可以大概估计,如果可以估计出一个节点到达目标的距离,哪怕是不太准确,那么对于搜索路径也是很有帮助的。
小明:另外,这里用到的f(n)、g(n)和h(n)具有什么物理含义吗?
艾博士:这三个函数都具有明确的物理含义,我们具体总结一下。g(n)表示的是从初始节点S到达节点n最短路径代价的估计值,通常为搜索图中已经找到的从S到n的路径代价。h(n)称作启发函数,表示的是从节点n到达目标节点T最短路径代价的估计值,该值的计算与具体问题有关。f(n)称作评价函数,表示的是从S出发、经过节点n到达目标节点T最短路径代价的估计值,该值通过累加g(n)和h(n)获得。f(n)是对节点n的总体评价,既考虑了从初始节点S到节点n的代价,又考虑从节点n到目标节点的代价,是对通过节点n到达目标节点最佳路径代价的估计,体现了节点n是否在到达目标节点最佳路径上的可能性。f(n)越小说明节点n在最佳路径上的可能性越大,因此优先扩展f(n)小的节点,是一个可行的搜索策略。
采用这样的搜索策略,每次优先选取f值最小的节点扩展,直到目标节点的f值最小为止,这样的搜索算法称作A算法。A算法与迪杰斯特拉算法的区别就是用节点的f值代替g值,每次选取f值最小的节点优先扩展。
小明有些着急地问:我觉得A算法中最重要的就是启发函数h(n)的计算,那么如何估计节点的h值呢?
看着小明的样子,艾博士安慰说:先不用着急,这个问题我们后面再详细讲解。先假定已经给出了节点的h值,看看A算法是如何工作的。
还是以上面说的问题为例,但是这次我们给出了每个节点的h值,如图3.12所示。

图3.12 给出了节点h值的示意图
艾博士对小明说:这次你尝试着用A算法求解一下试试。
小明马上找来一张纸画了起来,得到了图3.13所示的搜索图。
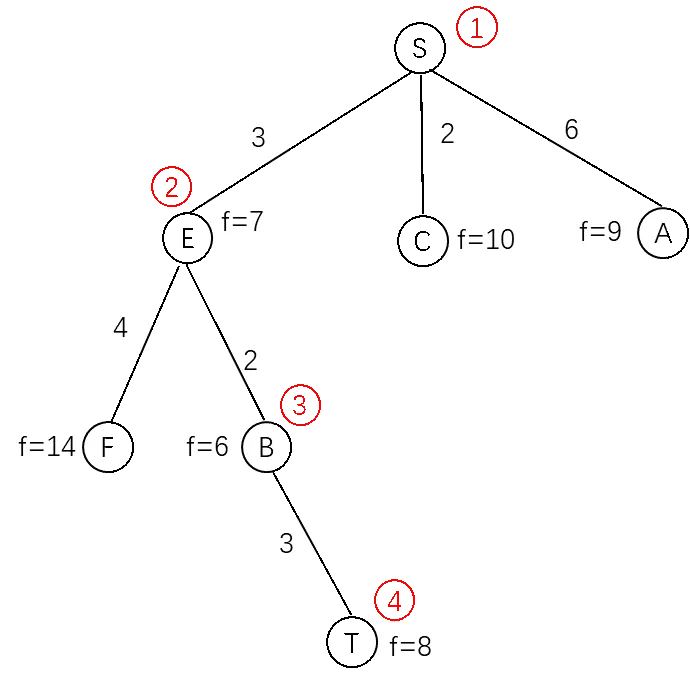
图3.13 A算法搜索示意图
艾博士对小明说:请你解释一下做的过程。
小明对照着图3.13解释说:首先以初始节点S建立根节点,计算S的f值:
f(S) = g(S) + h(S)
由于S是初始节点,所以g(S)=0,而h(S)图3.12中给出的结果是6,所以f(S)=6。这时待扩展节点只有一个节点S,选择S扩展,生成子节点A、C、E。分别计算这三个节点的f值:
f(A) = g(A) + h(A) = 6 + 3 = 9
f(C) = g(C) + h(C) = 2 + 8 = 10
f(E) = g(E) + h(E) = 3 + 4 = 7
从A、C、E三个待扩展节点中,选择f值最小的节点E优先扩展,生成子节点B、F。同样计算这两个节点的f值:
f(B) = g(B) + h(B) = 5 + 1 = 6
f(F) = g(F) + h(F) = 7 + 7 = 14
这样待扩展节点为A、C、B、F这4个节点。从中选择f值最小的B节点进行扩展,生成出节点T,计算T的f值:
f(T) = g(T) + h(T) = 8 + 0 = 8
此时待扩展节点为A、C、F、T四个节点,其中f值最小的是节点T,同时T也是目标节点,所以算法结束,得到路径S-E-B-T。
看到小明的求解结果,艾博士夸奖到:小明讲解的非常清楚,尤其最后特意指明f(T)最小才结束,这一点是非常重要的。
在A算法中,还有一些细节需要处理,为此我们先给出A算法的详细描述,以便说清楚这些细节。
在介绍算法之前,先介绍几个算法中用到的符号。S为给定的初始节点。OPEN是一个表,当前的待扩展节点放在该表中,并按照f值从小到大排列。CLOSED也是一个表,所有扩展过的节点放在该表中。
A算法:
1、初始化:OPEN=(S), CLOSED=( ),计算f(S);
2、循环做以下步骤直到OPEN为空结束:
3、循环开始
4、 从OPEN中取出第一节点,用n表示该节点;
5、 如果n就是目标节点,算法结束,输出节点n,算法成功结束;
6、 否则将n从OPEN中删除,放到CLOSED中;
7、 扩展节点n,生成出n的所有子节点,用 表示这些子节点;
8、 计算节点 mi 的f值,由于可能存在多个路径到达 mi ,用 f(n,mi) 表示经过节点n到达 mi 计算出的f值,不同的到达路径其 g(mi) 值可能不同,但是h(mi) 是一样的,因为 h(mi) 是从 mi 到目标节点路径代价的估计值,与如何从初始节点到达 mi 无关;
9、 如果 mi 既不在OPEN中,也不在CLOSED中,说明这是一个新出现的节点,则将 mi 加入到OPEN中,并标记 mi 的父节点为n;
10、 如果 mi 在OPEN中,并且 f(n,mi)<f(mi) ,则 f(mi)=f(n,mi) ,并标记 mi 的父节点为n;
11、 如果mi 在CLOSED中,并且f(n,mi) <f(mi) ,则 f(mi)=f(n,mi) ,并标记 mi 的父节点为n,将 mi 从CLOSED中删除、重新加入到OPEN中;
12、 对OPEN中的节点按照f值从小到大排序;
13、循环结束
14、没有找到解,算法以失败结束
下面我们对A算法做具体解释。
A算法的基本思想是从待扩展节点中,选一个f值最小的节点扩展。为了表述方便,我们将待扩展节点放在OPEN中,并对OPEN中的节点按照f值从小到大排序,这样OPEN中的第一个节点就是f值最小的节点。而被扩展的节点放在CLOSED中。最开始,待扩展节点只有初始节点S在OPEN中,CLOSED节点为空。
然后就是循环操作,每次从OPEN中取出第一个节点n,也就是f值最小的节点,首先判断n是否目标节点,如果是目标节点,输出该目标节点,A算法结束。否则就扩展节点n,产生n的所有子节点 mi ,然后将n从OPEN中删除,加入到CLOSED中。由于从S到达 mi 的路径可能有多个,通过不同路径计算的 g(mi) 也可能不同,计算出的f值也会不同。我们只需保留一个最小的f值即可。由于这次是通过节点n扩展出的 mi ,所以我们用 f(n,mi) 表示经过节点n到达 mi 计算出的f值。如果 mi 既不在OPEN中,也不在CLOSED中,说明 mi 是第一次出现的节点,直接将 mi 加入到OPEN中,并标记mi 的父节点为n,表示mi 是从n节点产生的。如果 mi 在OPEN中,说明到达 mi 至少有两条路径,之前已经从其他路径产生过节点 mi ,并且 mi 还没有被扩展过。通过之前路径计算的 f(mi) 与通过n节点这条新路径计算的 f(n,mi) 进行比较,哪个路径计算的f值小就保留哪条路径。如果以前路径计算的 f(mi) 小,就保持不变,忽略从n产生的 mi 这条路径。如果新路径的 f(n,mi) 小,就标记 mi 的父节点为n,并用 f(n,mi) 作为节点 mi 的f值。如果 mi 在CLOSED中,同样说明到达 mi 至少有两条路径。如果 mi 之前的f值小于新路径的f值 f(n,mi) ,则保持不变,忽略从n产生 mi 这条路径。如果新路径的 f(n,mi) 小,就标记 mi 的父节点为n,并用 f(n,mi) 作为节点mi 的f值。但是由于 mi 是在CLOSED中的,说明 mi 已经被扩展过,其子节点已经生成,如果 mi 的父节点被修改了,则到达 mi 的子节点及其后续节点(如果已经产生的话)的路径也被改变了,g值将有所变化,所以mi 的子节点及其后续节点的f值也应该有所改变。为了处理这种情况,A算法采用了一种简化处理的方法,先将 mi 从CLOSED中删除,然后将 mi 重新放回到OPEN中,当以后该节点排在OPEN中的第一位、 mi 节点再次被选择进行扩展时,重新生成其子节点,这时按照A算法自然就修改了mi 的子节点的f值,简化了A算法的处理过程。最后对OPEN中的节点按照f值大小进行排序,再次循环进行以上操作,直到算法结束。
A算法有两个结束出口,第一个出口是当OPEN的第一个节点是目标节点时,说明找到了从初始节点到目标节点的路径,算法找到解成功结束;第二个出口是,当OPEN中不含有任何节点,也就是OPEN为空时,算法退出循环结束,此时表示算法已经遍历了所有的可能,但是仍然没有找到解,算法失败结束。
介绍完A算法之后,艾博士再次强调说:请注意A算法的结束条件,必须是当目标节点的f值在OPEN中最小,也就是目标节点排在OPEN表的第一个位置时,算法才成功结束,而不是目标一出现就结束算法,这是初学者最容易犯的错误,一定要牢记这一点。该结束条件与迪杰斯特拉算法是一样的。
听了艾博士的讲解,小明说:谢谢艾博士的讲解,我记住这个结束条件。能否再举一个A算法求解的例子呢?
艾博士:好的,我们再举一个用A算法求解八数码问题的例子。该八数码问题如下:
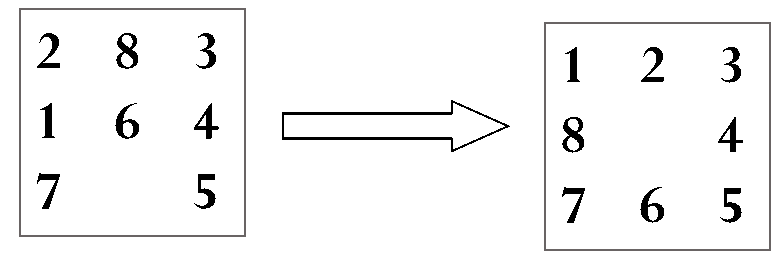
图3.14 八数码问题举例
艾博士:为了用A算法求解八数码问题,需要先定义h函数,以便计算f值。我们定义h函数为不在位的将牌数。也就是说,看一个状态的所有将牌所在的位置,与目标状态将牌所在位置进行比较,看有多少个将牌位置与目标状态不一致。不在位将牌的数量就是该状态的h值。比如图3.15所示的状态,与目标相比1、2、6、8四个将牌不在目标位置,所以该状态的h值就是4。由于八数码问题一次只能移动一个奖牌,在将牌移动一次的代价为1的情况下,不在位将牌数一定程度上体现了一个状态与目标状态的距离,可以用来估计其到达目标所需要的代价。
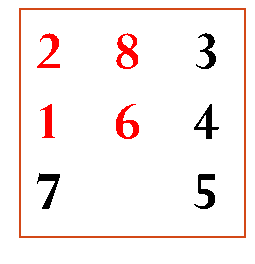
图3.15 不在位将牌数作为h函数计算举例
图3.16给出了采用A算法求解该八数码问题的搜索图。图中红圈中的数字表示节点被扩展的次序,英文字母旁括号中的数字表示计算出的该节点的f值。
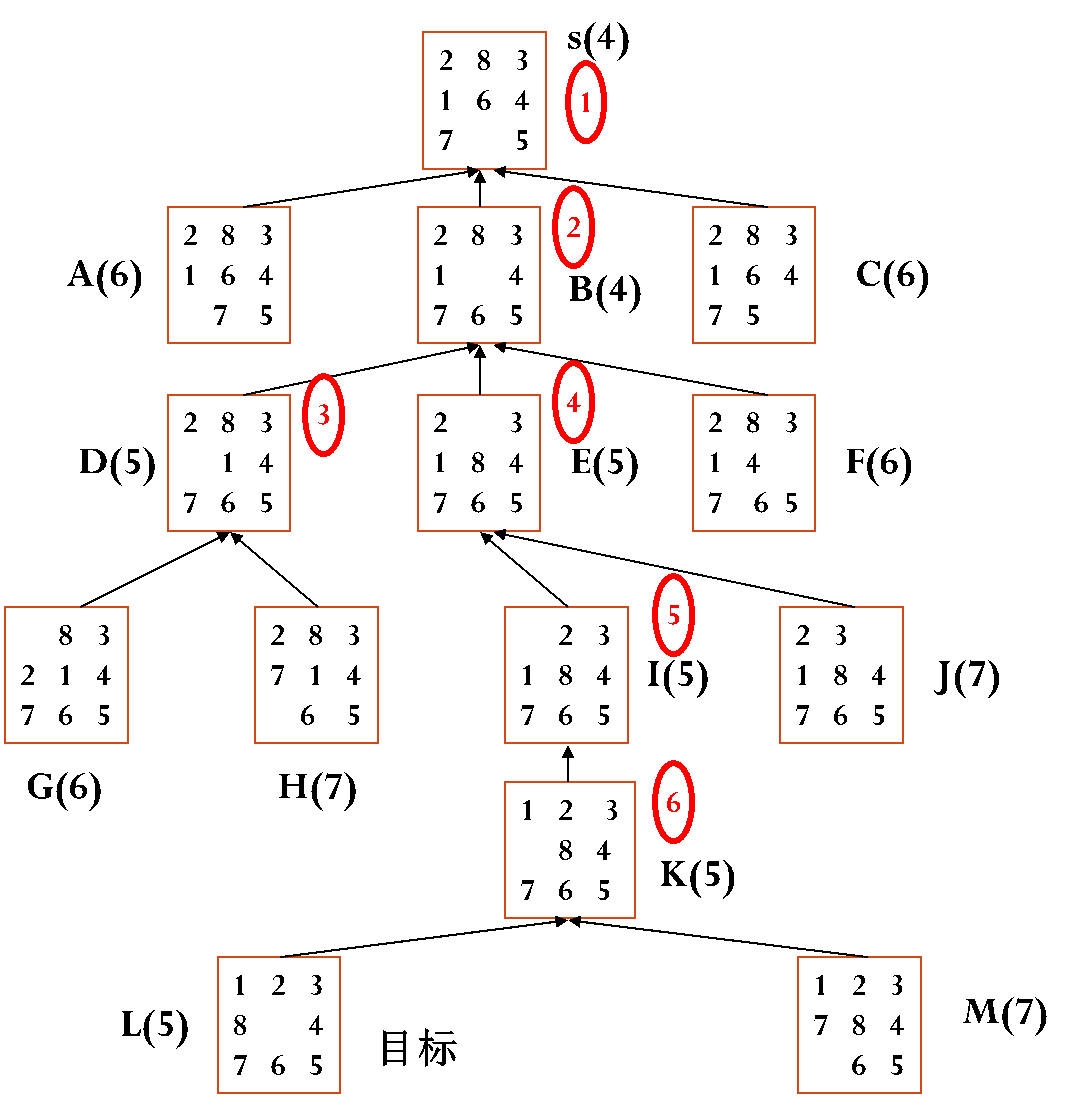
图3.16 A算法求解八数码问题的搜索图
按照A算法,S首先被扩展,产生A、B、C三个子节点,并标注这三个节点的父节点为S,图中用指向S的箭头表示,S被放入到CLOSED中。由于这三个节点都是经过一步产生的,所以g值都是1。节点A有1、2、6、7、8五个将牌不在位,所以h(A)=5,加上A的g值1,有f(A)=1+5=6,同理可以得到f(B)=4、f(C)=6。这样OPEN和CLOSED分别如下:
OPEN = (B(4), A(6), C(6))
CLOSED = (S(4))
从OPEN中取出第一个节点B(4)放入到CLOSED中,扩展B(4)生成子节点D、E、F,并标注这三个节点的父节点为B。这三个节点均是经过两步走成的,所以g值均为2。节点D、E都是1、2、8三个将牌不在位,所以h值都是3。节点F是1、2、4、8四个将牌不在位,其h值为4。这样得到f(D)=f(E)=2+3=5,f(F)=2+4=6。D(5)、E(5)、F(6)分别放到OPEN中并按照f值排序,有:
OPEN = (D(5), E(5), A(6), C(6), F(6))
CLOSED = (S(4), B(4))
从OPEN表中取出第一个节点D(5)放入到CLOSED中,扩展D(5)生成子节点G、H,并标注这两个节点的父节点为D,计算有f(G)=6、f(H)=7,分别放入到OPEN中并排序,有:
OPEN = (E(5), A(6), C(6), F(6), G(6), H(7))
CLOSED = (S(4), B(4), D(5))
从OPEN表中取出第一个节点E(5)放入到CLOSED中,扩展E(5)生成子节点I、J,并标注这两个节点的父节点为E,计算有f(I)=5、f(J)=7,分别放入到OPEN中并排序,有:
OPEN = (I(5), A(6), C(6), F(6), G(6), H(7), J(7))
CLOSED = (S(4), B(4), D(5), E(5))
从OPEN表中取出第一个节点I(5)放入到CLOSED中,扩展I(5)生成子节点K,并标注K的父节点为I,计算有f(K)=5,放入到OPEN中并排序,有:
OPEN = (K(5), A(6), C(6), F(6), G(6), H(7), J(7))
CLOSED = (S(4), B(4), D(5), E(5), I(5))
从OPEN表中取出第一个节点K(5)放入到CLOSED中,扩展K(5)生成子节点L、M,并标注这两个节点的父节点为K,计算有f(L)=5、f(M)=7,分别放入到OPEN中并排序,有:
OPEN = (L(5), A(6), C(6), F(6), G(6), H(7), J(7), M(7))
CLOSED = (S(4), B(4), D(5), E(5), I(5), K(5))
从OPEN中取出第一个节点L(5),发现L就是目标节点,算法结束输出目标节点L。
小明听着艾博士的讲解,对照着图3.16所示的搜索图说:不在位的将牌数虽然看起来是一个并不太准确的路径代价估计值,但是效果还是挺好的,看来A算法是一个不错的算法。但是我还有个问题,虽然A算法最终找到了目标节点,但是算法并没有说如何得到这条解路径,如何获得从初始节点到达目标节点的解路径呢?对于八数码问题来说,我们更关心的应该是如何移动将牌到达目标,而不是目标本身。
艾博士说:小明你提了一个很好的问题。虽然A算法并没有说如何得到解路径,但是保留了相关的信息。比如每个产生的节点都有一个父节点标记,算法成功结束时输出的是找到的目标节点,这样从目标节点开始,一步步沿着父节点标志反向寻找到初始节点,就得到了需要的解路径。
小明:我明白如何得到解路径了。对于图3.16所示的搜索图来说,算法输出的是目标节点L,由L知道其父节点是K,而K的父节点是I,以此类推,我们可以得到该问题解路径的逆序表示为L-K-I-E-B-S,将其反转过来就是S-B-E-I-K-L,就得到了该问题的解。也就是将牌6下走一步,将牌8下走一步,将牌2右走一步,将牌1上走一步,将牌8左走一步,就实现了从给定的初始状态通过将牌的移动达到目标状态。
2、A*算法
艾博士:小明,你发现没有,我们一直没有说A算法是否能够找到最优路径?
小明:确实啊。从前面的八数码问题例子看,A算法的求解效率还是很高的,但是是否能保证找到最优解呢?
艾博士:我们在解释一个节点的h值时,只说了是该节点到达目标节点路径代价的一个估计值,并没有对h函数做具体的限制。所以在对h函数没有任何限制的情况下,不好讨论A算法的性质。
可以证明,对于任何一个节点n,如果h(n)<=h*(n) 的话,则A算法一定可以在有解的情况下找到最优解,也就是代价最小的路径。其中h*(n)表示从节点n到达目标节点最优路径的代价。
当满足条件h(n)≤h*(n)时,A算法称作A*算法,其中h(n)≤h*(n)称作A*条件。
小明有些不太明白地问:当h函数满足A*条件时,A算法就是A*算法吗?
艾博士肯定地回答说:是的,从算法描述的角度来说,A*算法与A算法是完全一样的,只是对h函数加上了A*条件限制。
小明又有些疑惑地问到:一般来说,在求解之前我们并不知道 h*(n) 的具体大小,那么如何判断h函数是否满足A*条件呢?
艾博士:这又是一个很好的问题。我们需要根据具体问题具体判断。比如说我们在地图上用A*算法求给定两点的最短路径,假设我们知道每个路口,也就是节点的坐标的话,就可以将h函数定义为每个路口到达终点的欧氏距离。因为欧氏距离是两点间的最短距离,所以一个路口到达终点的实际最短距离不可能小于欧氏距离,所以这样的h函数是满足A*条件的。
再比如,在前面的八数码问题例子中,我们定义h函数为不在位的将牌数。由于八数码问题每次只能移动一步将牌,而移动一步将牌理想情况下最多也是把一个不在位的将牌移动到位,所以当有m个不在位将牌时,至少需要m步才可能把所有将牌移动到位,所以这样的h函数也是满足A*条件的。
小明:我明白了,判断一个h函数是否满足A*条件,需要根据具体问题具体分析,根据问题和定义的h函数判断是否满足A*条件。
艾博士肯定地说:就是这样的。
3、定义h函数的一般原则
小明又问艾博士:A*算法最重要的就是一个满足A*条件的h函数。那么应该如何定义h函数呢?
艾博士:如何定义h函数是A*算法应用中最重要的内容,只能根据具体问题具体讨论。但是还是有一搬原则的。
小明忙问到:有哪些一般原则呢?
艾博士:一个重要的原则可以总结为:放宽原问题的限制条件,在宽条件下求解一个状态到目标状态的最优路径代价,以此代价作为该状态的h值。在宽条件下求解的最小代价,不会比严格条件下的最小代价大,所以这样得到的h函数肯定可以满足A*条件。
小明:应该怎样放宽条件呢?
艾博士:这个问题比较重要,而且与具体问题有关,我们通过几个例子加以说明,从简单问题到复杂一些的问题。
(1)地图上求解两点间的最优路径问题
艾博士:地图上求解两点间的最优路径问题,其限制条件是必须沿着道路前进,道路不一定是笔直的,可能有弯曲,甚至在某段路可能会向相反的方向行进。我们可以放宽这个条件,比如任何两点间都可以直行,不必沿着道路行进。这样放宽条件后,任何一个路口到终点的路径最小代价都可以用欧氏距离计算,该距离一定不会大于严格条件下最优路径的代价,所以用欧氏距离定义h函数一定可以满足A*条件。
小明:这里例子比较容易理解,欧氏距离肯定是两点间的最短距离。
(2)八数码问题
艾博士:八数码问题的限制条件是将牌每次只能移动一步,而且只能移动到空格位置。我们把这一限制条件放宽,每个将牌可以“跳跃”,从当前位置跳跃到目标位置,而且不管目标位置是否有其他将牌存在,都可以跳跃过去。这样当有m个将牌不在位时,采用这种跳跃的方式,最多经过m次跳跃,就达到了目标状态。因此这种宽条件下所移动的将牌次数不会多于原问题严格条件下的将牌移动次数,所以用不在位的将牌数定义h函数,可以满足A*条件,而且不在位将牌的多少,也一定程度上反应了该状态到达目标状态的距离。
小明问:对于八数码问题来说,将限制放宽到可以跳跃,似乎条件放的太宽了,是否可以收紧一些呢?
艾博士:这正是我想要说的,其实条件可以再收紧一些。八数码问题将牌每次只能移动一步,我们可以继续保留这个限制,但是放宽只能移动到空格位置这个条件,也就是不管旁边位置是否有将牌,都可以移动过去。在这样的宽松条件下,每个不在位的将牌需要移动k步到达目标位置,而k就是该将牌到达目标位置的距离。所以我们可以用每个不在位将牌到其目标位置的距离和来定义h函数。这是在宽松条件下达到目标状态所需要的最小代价,所以一定不会多于严格条件下所需要的代价,满足A*条件。
下面我们举例说明这种情况下如何计算一个状态的h值。在图3.17给出的例子中,1、2、6、8四个将牌不在位,其中1、2、6三个将牌距离目标位置均为1,也就是经过1步移动就可以到达目标位置,将牌8需要移动两步才能到达目标位置,所以将牌8到达目标位置的距离为2,这样四个不在位将牌距离目标位置的距离和为1+1+1+2=5,则该状态的h值为5。
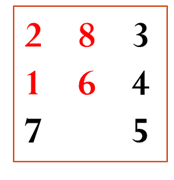
图3.17 用不在位将牌距离目标位置距离和作为h函数计算举例
小明:八数码问题这两个例子很好地说明了如何通过放宽条件,在宽松条件下定义h函数的问题,很受启发,大概了解了如何定义h函数的思路了。
(3)传教士与野人问题
艾博士:下面我们再举一个稍微复杂一点的例子——传教士与野人问题。
传教士与野人问题描述如下:
有5个传教士和5个野人来到河边准备渡河,河岸有一条船,每次至多可供3人乘渡。问如何规划摆渡方案,使得任何时刻,在河的两岸以及船上的野人数目总是不超过传教士的数目(但允许在河的某一岸或者船上只有野人而没有传教士)。假设传教士和野人都会划船,而没有传教士和野人以外的其他划船人。
在这里我们主要讨论如何设计h函数,以便可以用A*算法求解该问题。
我们假设开始时传教士和野人在河的左岸,目标是乘船到达河的右岸。由于总人数是固定的,所以我们可以考虑用左岸传教士和野人的人数、以及船在河的哪边表示一个状态。比如表达为一个如下的三元组:
(M, C, B)
其中M、C分别表示在左岸的传教士和野人人数,B表示船在河的哪一边,船在左岸时B等于1,船在右岸时B等于0。
该问题的一个特点是船在河的两岸转换,如果这个状态船在左岸,则下一个状态船在右岸;如果这个状态船在右岸,则下一个状态船在左岸。所以在定义h函数时要考虑到这种情况,需要分别考虑船在不同的岸边的情况。同时我们假设,摆渡一次船的代价为1,而不考虑船上具体有多少人。
如何通过放宽条件的方法得到该问题的h函数呢?
对于传教士和野人问题,主要的限制条件是在摆渡的过程中“在河的两岸以及船上的野人数目总是不超过传教士的数目”,我们将这个限制条件去掉,只考虑船每次最多可供3人乘渡这一个条件。
先考虑船在左岸的情况。如果不考虑限制条件,也就是说,船一次可以将三人从左岸运到右岸,然后再有一个人将船送回来。这样,船一个来回可以将2人运过河,而船仍然在左岸。而最后剩下的三个人,则可以一次将他们全部从左岸运到右岸。所以,在不考虑限制条件的情况下,至少需要摆渡 [(M+c-3)/2]*2+1 次。其中分子上的“-3”表示剩下三人留待最后一次运过去。除以“2”是因为一个来回可以运过去2人,需要 (M+c-3)/2 个来回把除了最后三人外的其他所有人运送过去,而“来回”数不能是小数,需要向上取整,这个用 [] 符号表示。而乘以“2”是因为一个来回相当于两次摆渡,总代价要乘以2。而最后的“+1”,则表示将剩下的3人运过去,需要一次摆渡。可以说, [(M+c-3)/2]*2+1 是在宽松条件下,把所有的传教士和野人全部从左岸摆渡到右岸所需要的最小摆渡次数。
化简有:
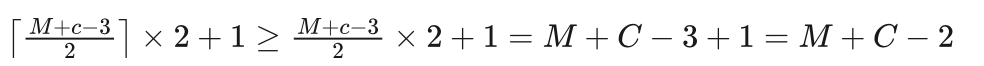
所以,当状态是船在左岸时,需要的摆渡次数至少需要M+C-2次,其中M、C分别为当前状态在左岸的传教士和野人人数。
再考虑船在右岸的情况。同样不考虑限制条件。船在右岸,需要一个人将船运到左岸。因此对于状态(M,C,0)来说,其下一个状态是(M+1,C,1)或者是(M,C+1,1),具体看是传教士将船运到左岸,还是野人将船运到左岸,在宽松条件下我们并不需要具体区分这两种情况,我们假设下一个状态为(M+1,C,1),这时就相当于船在左岸的情况了。按照前面的分析,我们将此时左岸的传教士人数M+1和野人人数C带入上面分析的船在左岸的情况,可以得到对于状态(M+1,C,1)至少需要(M+1)+C-2次摆渡。但是我们需要计算的是船在右岸时状态(M,C,0)所需要的最少摆渡次数,而状态(M+1,C,1)是状态(M,C,0)经过一次摆渡达到的,所以(M+1,C,1)所需要的最少摆渡次数加1,就是(M,C,0)所需要的最少摆渡次数。所以有(M,C,0)需要的最少摆渡次数为(M+1)+C-2+1,化简有M+C。
总结以上情况我们有:
对于船在左岸时的状态(M,C,1),需要的最少摆渡次数为M+C-2。
对于船在右岸时的状态(M,C,0),需要的最少摆渡次数为M+C。
考虑到船在左岸时,B=1,船在右岸时,B=0。两种情况可以综合在一起,状态(M, C, B)需要的最少摆渡次数为M+C-2B。
由于该摆渡次数是在不考虑限制条件下,推出的最少所需要的摆渡次数。因此,当有限制条件时,最优的摆渡次数不可能小于该摆渡次数。所以这样定义的h函数一定满足A*条件。
小明:这个例子确实有点复杂,但也可以很好地体现通过放宽限制条件定义h函数的思想。
4、h函数的评价
听完艾博士的介绍,小明又提出了一个问题:对于同一个问题,可以定义不同的h函数,比如对于八数码问题,我们就定义了“不在位的将牌数”和“不在位将牌距离目标位置的距离和”两个h函数。从感觉上来看,“不在位将牌距离目标位置的距离和”由于考虑了将牌到目标位置的距离应该更好一些。那么有什么方法评价两个h函数的好坏吗?
艾博士:小明你这个问题非常好,当对于同一个问题定义了多个不同的h函数时,确实应该有个比较方法判断哪个h函数更好一些。
对于这个问题,首先要定义评价h好坏的标准。我们定义h函数的目的就是通过A*算法尽快找到问题的解,所以可以用扩展的节点数作为评判标准。对于同一个问题如果定义了两个不同的h函数,用其中一个h函数扩展的节点数少于用另一个h函数扩展的节点数,则说明前一个h函数更好。
对此我们有如下的定理:
设对同一个问题定义了两个满足A*条件的h函数h1 和 h2 ,如果对所有非目标节点有h2(n) > h1(n),则当A*算法结束时,用 h2 扩展的每一个节点,也必定由 h1 所扩展,即用 h1 扩展的节点数≥用 h2 扩展的节点数。
这里“用 hi 扩展的节点”的含义是,当h函数采用 hi 时,A*算法所扩展的节点。
由于两个h函数均满足A*条件,所以取值越大的h函数,说明对最小路径代价的估值越准确。该定理表明,估计越准确的h函数,其性能越好。
小明又问到:艾博士,定理中要求对于所有非目标节点有h2(n)>h1(n) ,也就是要求 h2(n) 恒大于 h1(n) ,这里可以加上等号吗?即h2(n)>=h1(n) 。
艾博士摇了摇头说:是不可以的,因为我们可以很容易举出反例来。小明你还记得我们反复强调过的A*算法的结束条件吗?
小明:您强调过多次这个问题,只有当目标节点排在OPEN的第一个位置时算法才成功结束。
艾博士:是的,这一点很重要,是A*算法可以找到最优解的一个重要条件。但是当多个节点的f值相等时,这些节点在OPEN中如何排序,算法并没有说明。问题也就出现在这里。比如有非目标节点m,刚好有f(m)=f(T),其中T是目标节点。在这种情况下,如果m在OPEN中排在了T的前面,则A*算法将会扩展m节点;如果m排在了T的后面,则T被从OPEN中取出后算法就结束了,节点m并不会被扩展。如果 h2(n)>=h1(n) ,并且刚好有 f1(m)=f2(m) ,其中f1 、f2 分别指用h1 、h2 计算的f值。由于m排序位置的不确定性,可能会导致h2 扩展了m节点,但是 h1 不扩展m的情况发生,这样定理就不成立了。所以这个等号是不能加的。但是,如果对排序结果加以干预,遇到这样的节点m时,均排在目标节点的后边,则即便加上等号定理也同样成立。
小明:这么一解释就明白了为什么定理中不能加上等号了。
艾博士举例说:比如对于前面八数码的例子,我们定义:
h1 =“不在位将牌数”
h2 =“不在位将牌距离目标位置的距离和”
满足 h2(n)>=h1(n) ,并不符合定理的条件,所以也就不能保证 h2 的性能不会比 h1 差,但是如果像上面介绍的一样,对排序结果加以干预的话,则 h2 的性能一定不会比 h1 差。
艾博士:这里我们再强调一下,在这个定理中说的是“扩展的节点数”而不是“扩展的节点次数”。
小明:这两个有什么区别呢?
艾博士:在后面我们会看到,A*算法可能会存在重复扩展节点问题,也就是说,某个节点可能会被重复多次扩展。“扩展的节点数”指的是有多少个节点被扩展了,而不考虑一个节点被扩展了多少次。而“扩展的节点次数”指的则是节点扩展依次计算一次,如果有重复扩展节点的情况,则也要计算在内。比如A节点被扩展了3次,B节点被扩展了2次,从“扩展的节点数”角度考虑,则是只有两个节点被扩展,也就是说扩展的节点数为2。而从“扩展的节点次数”角度考虑,则是一共扩展了5次节点。上述定理是说,当 h2(n)> h1(n)时,用 h2 扩展的节点数不大于用h1 扩展的节点数,没有考虑节点被重复扩展的情况。
小明:我明白了,如果不是艾博士强调,还真没有注意到这个问题。在实际问题中,情况可能比较复杂,可能并不容易比较两个h函数的大小。或者出现这种情况,总体上 h2 比较大,但是个别情况下也存在小于 h1 的情况,这时有什么方法判断哪个h函数更好吗?
艾博士:这时可以采用实验的方式进行比较,找出一个相对好的h函数。为了方便测试比较,同样需要有一个评价指标。我们看看有什么样的指标可以使用。
图3.18给出了一个深度为3的满二叉树示意图。
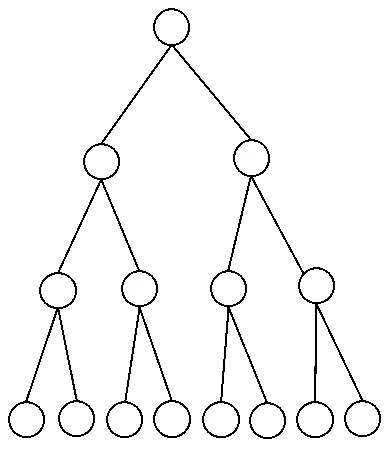
图3.18 二叉树示意图
小明不解地问:满二叉树是什么意思呢?
艾博士:所谓二叉树,就是每个节点最多只有两个子节点的树,而满二叉树指的是除了叶节点(也就是最下面的节点)外,每个节点都有两个子节点,且所有叶节点的深度都是一样的树。一般情况下,我们也可以定义深度为d的满b叉树。
艾博士接着介绍说:对于一个深度为d的满b叉树,其节点总数N可以由下式给出:
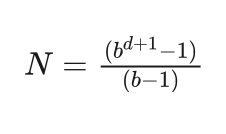
如果我们把深度为d的满b叉树想象成是一个目标节点深度为d的搜索图,则b越大搜索的范围越多,求解效率就越低。相反,如果b越小,则搜索的范围越小,求解效率就越高。因此我们希望b越小越好。
对于一个实际搜索图来说,不可能刚好是一个b叉树,但是我们可以根据搜索图中总的节点数以及目标节点的深度,按照上式求解一个分叉的平均值,就是当搜索图中节点总数为N、目标节点深度为d时,所对应的平均分叉数满足上述公式。这样我们就可以用平均分叉数的大小来评价h函数的搜索效果了。
小明:怎么评价呢?请您具体讲讲。
艾博士:简单说就是,对于给定的问题,定义一个h函数,用该h函数进行A*搜索,A*算法结束时可以得到共产生了多少个节点N,以及目标节点所在的深度d。将N和d带入到公式:
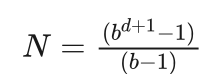
中,就可以计算出平均分叉数b。不过根据该式并不能求出b的解析表达式,只能通过数值计算的方法计算出b值。b越小就说明该h函数越好。
小明:按照这个公式求得的平均分叉数一定是整数吗?
艾博士:不是的,应该绝大多数情况下不是整数,除非遇到很特殊的情况,因为这是一个平均的概念。
我们还是以八数码问题为例,设h函数分别为:
h1 =“不在位将牌数”
h2 =“不在位将牌距离目标位置的距离和”
我们随机生成2个八数码问题的初始状态,最佳解路径的长度分别为14和20,分别采用两个不同的h函数用A*算法求解,并计算不同情况下的平均分叉数b。结果如下表所示。
表3.1 八数码问题不同h函数时的平均分叉数
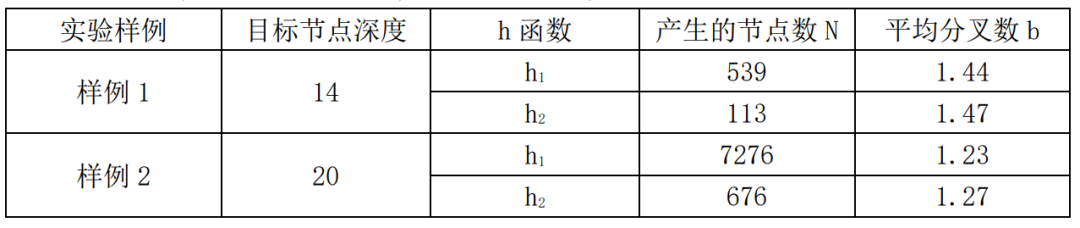
从表中可以看出,采用 h2 时效果明显好于 h1 的效果,这与我们的直觉也是一致的。对于不同深度的目标节点,当采用同一个h函数时,求得的平均分叉数b也是基本相同的,变化并不大,说明平均分叉数是一个比较好的评价指标。
小明:就是说当我们不能从理论上评价两个h函数的好坏时,可以通过实验求取平均分叉数的方法评价,平均分叉数越小的h函数越好。
未完待续