
第二篇 计算机是如何学会下棋的(三)
清华大学计算机系 马少平
第三节:α-β剪枝算法
听了艾博士说的结论,小明不免有些沮丧:原来以为这样就可以实现计算机下棋了,原来还是不行啊。
艾博士回答说:小明你不要沮丧,有困难不怕,想办法解决就是了。请再想想,刚才你提到你下棋时只能考虑4、5步,但是这4、5步棋中是所有情况都考虑吗?
小明回答说:那肯定不是,所有可能的走步都考虑的话,我根本就记不住,只是考虑我觉得最重要的几步棋吧?比如下象棋时,开始几步我可能只考虑炮、马、车等,肯定不会考虑帅、士等。
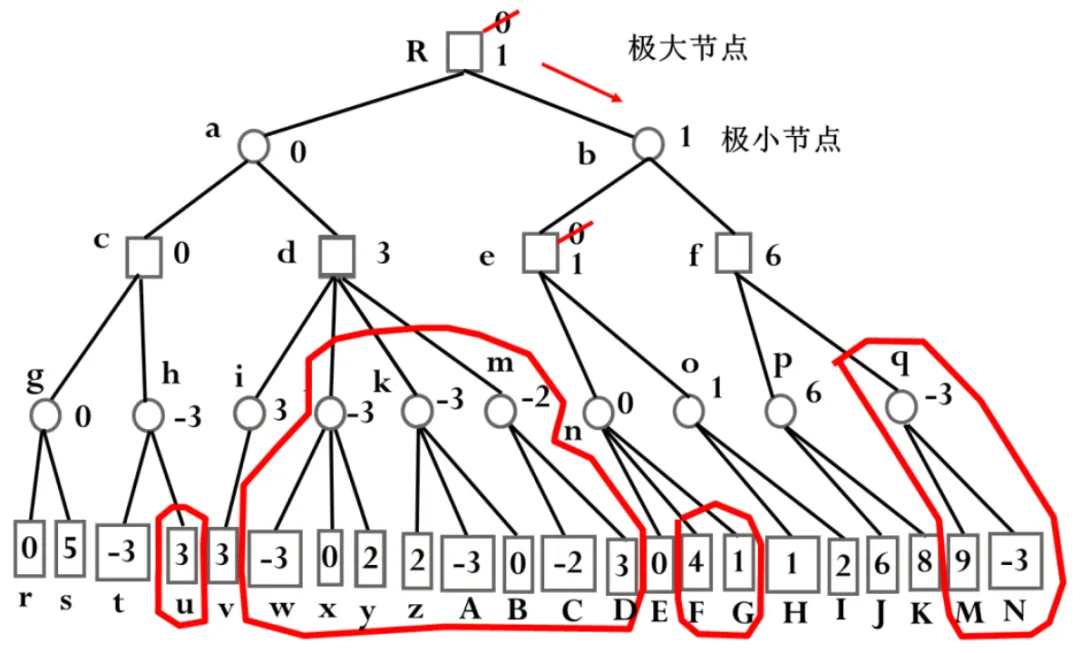
图2.6 α-β剪枝示意图
艾博士说:人类棋手在下棋时,会根据自己的经验只考虑在当前棋局下最重要的几个可能的走法,但是计算机没有这种经验。
小明还不等艾博士说完就问到:那要总结知识让计算机使用吗?
艾博士:这类知识太复杂了,需要考虑很多具体的情况,一旦知识总结的不到位,可能就会出现大的差错,这条路应该是走不通的。
小明:那就不知道怎么办好了。
艾博士:小明你别着急,我们再想想看是否有其他办法。我们换一个思路,假设并不是一开始就将整个搜索图生成出来,而是按照一定的原则一点一点地产生。比如图2.6是一个搜索图,我们假设一开始并没有这个图,而是按照从上到下从左到右的优先顺序来生成这个图。我们先从最上边一个节点开始,按顺序产生a、c、g、r四个节点,假设就考虑4步棋,这时就不再向下生成节点了。由于r的分值为0,而g是极小节点,所以我们知道g的分值应该≤0。接下来再生成s节点,由于s的分值为5,g是极小节点且没有其他子节点了,所以g的分值等于0。由于c是极大节点,根据g的分值为0,我们有c的分值≥0。再看c的其他后辈节点情况,生成h和t两个节点,由于t的分值为-3,而h是极小节点,所以有h的分值≤-3。
到这里,小明你注意一下:c的分值≥0,而h的分值≤-3,所以这时是不是u的分值是多少都无关紧要了?
小明仔细想了一下说:确实是这样。图中u的分值如果大于h的当前分值-3,则不影响h的分值,即便u的分值小于-3,比如-5,虽然改变了h的分值为≤-5,但是由于c是极大节点,c的当前分值已经至少为0了,所以h的分值变小也不会改变c的分值。
艾博士说:小明分析的很正确。这样的话,遇到图中这种h的当前分值小于c的当前分值这种情况时,由于u的分值是多少都不会影响c的分值了,所以就没有必要生成u这个节点了。这种情况我们称之为剪枝,其剪枝条件是如果一个后辈的极小节点(如图中的h),其当前的分值小于等于其祖先极大节点的分值时(如图中的c),则该后辈节点的其余子节点(如图中的u)就没有必要生成了,可以被剪掉。注意我们这里用的是后辈节点和祖先节点,这是一种推广,因为这种剪枝并不局限于父节点和子节点的关系,后面我们会有例子。
在确认了c的分值为0之后,同样的理由,我们可以确认a的分值≤0。生成a的后辈节点d、i、v,由于v的分值为3,且d向下就一条路,所以有d的分值≥3。由于a的分值最大为0,而d的分值最小为3,所以大的红圈圈起来的那些分支的分值是多少又没有意义了,a取c和d中分值最小的,最终a取值为0,大红圈圈起来的部分都没有必要生成了,又可以被剪掉。这里我们又发现了另外一个剪枝条件:如果一个后辈的极大节点的分值(如图中节点d)大于等于其祖先极小节点的分值时(如图中节点a),则该后辈节点还没有被生成的节点可以被剪掉,如图中大红圈圈起来的那些节点。
a的分值被确定为0之后,就可以确定R的分值≥0,继续向下生成节点b、e、n、E,由于E的分值为0,所以有n的分值≤0。n是极小节点,其极大节点祖先有e和R,e这时还没有值,但是R的分值≥0,所以满足后辈极小节点的分值小于等于其祖先极大节点分值的剪枝条件,n的两个子节点F和G都没有生成的必要,又可以被剪掉了。
小明插话说:艾博士,我明白了,你前面讲到剪枝条件时提到不只是跟父节点做比较而是要考虑祖先节点,就是这种情况吧?
艾博士回答说:对,这一点是非常需要注意的,很容易被初学者漏掉。
艾博士接着讲:n的分值被确定为0,从而有e的分值≥0。接着生成节点o和H,由于H的分值为1,有o的分值≤1,不满足剪枝条件,生成节点I,I的分值为2,o是极小节点,所以o的分值确定为1。e是极大节点,从n和o的分值中选取最大的,从而更新e的取值,由原来的0修改为1。e的分值确定为1后,有b的分值≤1。继续生成b的后辈节点f、P、J,J的分值为6,得到P的分值≤6,不满足剪枝条件,继续生成子节点K,得到K的分值为8,P是极小节点,选取子节点中最小的值6,从而确定f的分值≥6。后辈极大节点f的分值6大于等于其前辈极小节点b的分值1,满足剪枝条件,q、M、N三个节点被剪枝,从而确定b的分值为1。R的分值取a、b中最大者,从而用从节点b得到的1代替原来从a得到的0。搜索过程到此结束,按照刚才的搜索结果,甲方应该选择b作为行棋的最佳走步,如图2.6中的红色箭头所示。
这种方法就是α-β剪枝算法,可以利用已有的搜索结果,剪掉一些不必要的分枝,有效提高了搜索效率。
小明:深蓝就是采用的这种算法吗?
艾博士说:是的,深蓝就是用了α-β剪枝算法,从而可以在规定的时间内完成一次行棋过程。
小明又问道:艾博士,那么这种α-β剪枝算法得到的最佳走步跟极小-极大模型得到的结果是一样的吗?
艾博士说:这是个很好的问题,从前面的介绍可以知道,α-β剪枝只是剪掉了那些不改变结果的分枝,所以不影响最终选择的走步,得到的走步与极小-极大模型是一样的。
小明:我还有个疑问,就是那些分值是如何得到的呢?何处发生剪枝完全取决于那些分值,如果分值不准确则得到的结果也就值得怀疑了。
艾博士:小明你说的非常正确,这些分值是非常重要的。据深蓝的研发者介绍说,他们聘请了好几位国际象棋大师帮助他们整理知识,用于估算分值。但是基本思想并不复杂,大概就是根据甲乙双方剩余棋子进行加权求和,比如一个皇后算10分,一个车算7分,一个马算4分等。然后还要考虑棋子是否具有保护,比如两个相互保护的马,分数会更高一些,其他棋子也是大体如此。然后再考虑各种残局等,按照残局的结果进行估分。当然,这里我们给出的各个棋子的分数只是大概而已。最后甲方得分减去乙方得分就是该棋局的分值。
小明:我大概明白了,这个估值虽然看起来有些粗糙,但是由于在剪枝过程中探索的比较深,对于象棋来说,无论是国际象棋还是中国象棋,在探索的比较深的情况下,凭借棋子的多少基本就可以评判局面的优劣了,所以可以得到比较准确的估值。
艾博士补充说道:所以对于计算机下棋来说,探索的越深其棋力也就越强,在可能的情况下,应该尽可能探索的更深一些。
最后艾博士总结说:我再把α-β剪枝的关键点总结一下:
(1)在判断是否剪枝时,都是后辈极小节点与祖先极大节点进行比较、后辈极大节点与祖先极小节点做比较。当后辈极小节点的值小于等于祖先极大节点的值时,发生剪枝;当后辈极大节点的值大于等于前辈极小节点的值时,发生剪枝。
(2)在判断是否剪枝时,一定要注意不只是与父节点做比较,还要考虑祖先节点。
(3)在完成一次α-β剪枝后,只是选择了一次行棋,下一次应该走什么棋,应该在对方走完一步棋后,根据棋局变化进行α-β剪枝过程,再次根据搜索结果确定走什么棋。
小明读书笔记
对于真实的棋类游戏,由于其状态数过于庞大,不可能通过穷举所有状态的方法获得最佳走步。受人类下棋时思考过程的启发,提出了计算机下棋的极小-极大模型。该模型只在有限步内搜索,获得有限范围内的最佳走步。但同样由于棋类变化太多,即便是有限范围的搜索也是非常花费时间的。人类棋手在做极小-极大搜索的时候,并不是考虑有限范围内的每一种可能的走法,而是根据经验砍掉大量的不合理分枝,从而极大地缩小了搜索范围。受此启发提出了α-β剪枝算法,与人类利用经验砍掉大量不合理分枝不同,计算机并没有这种经验,而是利用已有的搜索结果,砍掉没有必要产生的分枝,有效地提高了搜索效率。深蓝就是采用的这种方法。
α-β剪枝条件:
当后辈的极小节点值小于等于其祖先的极大节点值时,发生剪枝。
当后辈的极大节点值大于等于其祖先的极小节点值时,发生剪枝。
注意:比较时不只是与其父节点做比较,还要与其祖先节点做比较,只要有一个祖先节点满足比较的条件,就发生剪枝。
α-β剪枝算法所得到的最佳走步质量严重依赖于最底层节点估值的准确性,搜索的越深,估值越准确。这是因为越深的节点其对应的棋局中棋子越少,而棋子比较少的情况下,其局面的估值也就会比较准确。这与人下棋时的思考也是一致的。
α-β剪枝算法结束时得到的只是当前棋局下的一步走法,相当于我们思考了半天决定了一步棋如何走,后面如何进行,需要待对方走完一步棋后再次进行α-β剪枝搜索获得下一步棋的走法。也就是说,每行棋一次都需要进行一次α-β剪枝搜索。
未完待续