所有事情具有多重属性:一只小鸟,我们看到它振翅的模样,听到它啾啾的鸣声,触摸起来有温柔的绒毛感觉。再比如,一只西瓜,样子是圆圆的,敲起来有嘭嘭的声音,尝一口甜美多汁。在很多情况下,我们需要利用多重属性,才能对事物有很好的认知。例如,圆圆的未必是西瓜,还可能是地雷;但如果圆圆的还甜美多汁,就不太可能是地雷了,是不是?每一种独特的属性称为一种“模态”,综合利用多模态信息的学习就是多模态学习。
人类是多模态学习的高手。我们用眼睛看,用耳朵听,用鼻子闻气味,用舌头尝味道,用皮肤进行碰触,这些感觉器官收到的信息传入我们的大脑,形成庞大的多模态数据流,我们的大脑就像一台高速计算机,一刻不停地对这些数据进行解析。在解析过程中,各个模态的数据互相补充,互相印证,最终形成“这是一只鸟”,“那是一只西瓜”的感知结论。
事实上,我们的大脑已经无比熟悉这一多模态处理过程,如果哪一天哪个模态出了问题,将极大影响我们的生活。如果不相信,可以把自己的眼睛蒙上三天试一试。就算是模态间出了一点点不匹配,都会带来很强的不适应。1976年,McGurk做了一个实验,让一个人发“fa”的音,但展示出的口唇运动是“ba”,这时听众基本上把这个音听成“va”。这一现象即是著名的McGurk效性[1]。McGurk效应证明当视觉和听觉出现错位时,我们的大脑有可能产生紊乱的错觉。
图1:McGurk效应[1]
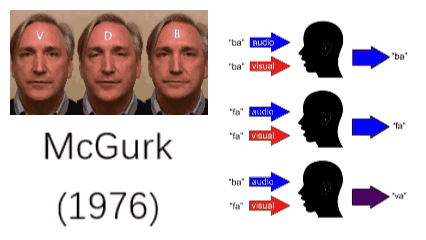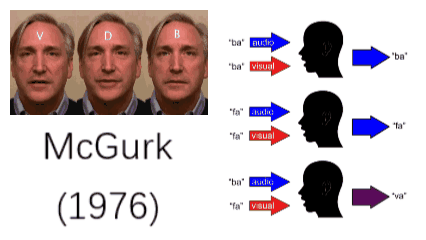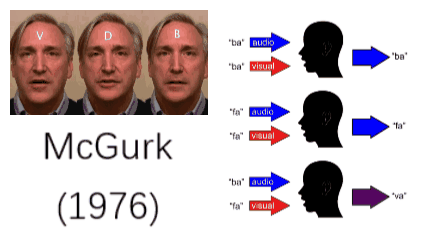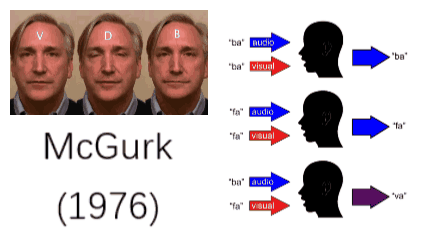
人们很早就注意到了多模态的重要性,并希望计算机也具有多模态学习的能力。例如,Google的研究者将听觉和视觉信息结合起来,通过观察发音人的口唇运动将目标发音人的声音从一堆混杂的声音中分离出来。这类似于在嘈杂的环境中,人们会不自觉地关注说话人的口唇,通过嘴型来猜测对方的发音。
图2:Google的Looking to Listen系统,通过发音人的口唇分离混合发音[2,3]。

另一个例子是用多模态信息判断人的情绪。人的情绪通常是很微妙的,有的人喜怒不形于色,但会表达在语言中;有的人可能不善言辞,但表达激烈。最近美国马里兰大学的研究者发表了一项工作,将面部表情、发音内容和声音特性融合起来,共同判断人的情绪。在一个称为IEMOCAP的数据集上,达到平均80%以上的正确率,而单一的声音模态正确率只有60%左右[5]。
从某种意义上讲,基于多模态的学习和推理是未来人工智能的大势所趋。一方面,每种模态信息都有局限性,利用不同信息之间的互补关系,可望大规模提高系统性能;另一方面,多种感知设备的普及为多模态处理提供了更大的舞台。
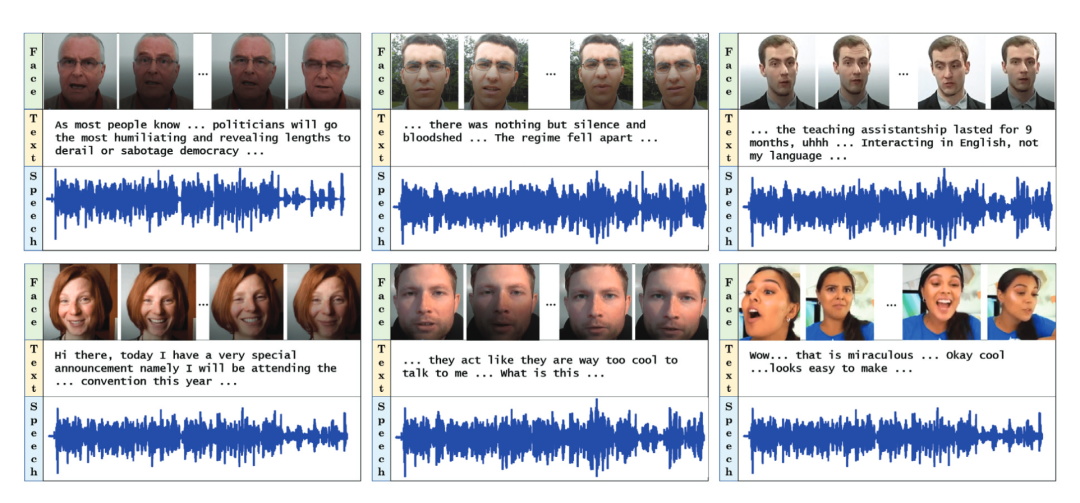
图3:马里兰大学的M3E系统视频、文本、声音通过三种模态来识别人的情绪
参考文献:
[1] McGurk H, MacDonald J. Hearing lips and seeing voices[J]. Nature, 1976, 264(5588): 746-748.
[2] Ephrat A, Mosseri I, Lang O, et al. Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation[J]. arXiv preprint arXiv:1804.03619, 2018.
[3]https://www.youtube.com/watch?v=rVQVAPiJWKU
[4] Mittal T, Bhattacharya U, Chandra R, et al. M3er: Multiplicative multimodal emotion recognition using facial, textual, and speech cues[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(02): 1359-1367.
[5]Yoon S, Byun S, Dey S, et al. Speech emotion recognition using multi-hop attention mechanism[C]//ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019: 2822-2826.
By:清华大学 王东