近年来,一个叫RAG(检索增强生成,Retrieval Augmented Generation)的技术突然走红。它到底是什么呢?简单来说,RAG通过引入检索功能来提升生成模型的表现。生成模型不仅包括像ChatGPT这样的文本生成器,还涵盖图像生成模型DALL-E和视频生成模型SORA等。
下图是RAG的典型结构,我们来看看它是如何工作的。用户输入一个问题或指令,系统中的“检索器”(Retriever)根据这个输入从外部知识库中找到相关资料。这些资料可能是互联网上的公开文档,也可能是用户数据库中的个人数据。然后,系统将最相关的内容和用户的原始输入一起送入生成模型,便可得到更加精准、质量更高的生成结果。
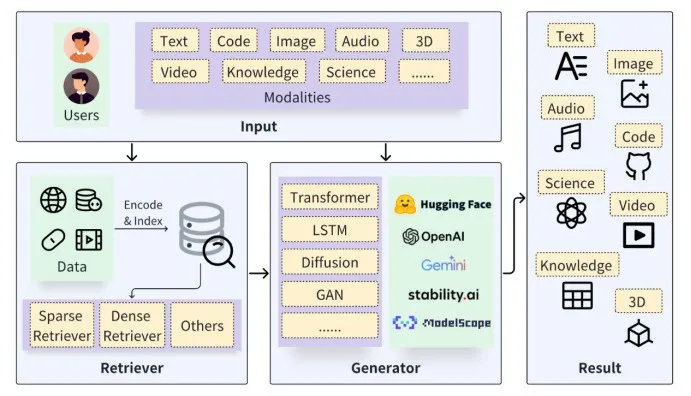
那么,为什么这些强大的生成模型还需要“检索”来帮忙呢?比如GPT-4,它拥有1.8万亿的参数,能够生成对话、文案、小说、诗歌等,似乎无所不能。然而,即便如此,这些大模型也有自己的烦恼。
首先,大模型的训练极其复杂,耗费资源极大。即使像OpenAI这些不缺钱的公司,要训练一个几万亿参数的大模型也非常吃力,所以这些大模型不可能频繁更新。因此,大模型所依赖的知识常常会过时。通过引入检索功能,把最新知识通过检索的方式送给大模型,使它可以实时访问最新的信息,使得生成结果更加“与时俱进”。
其次,大模型有时会“脑补”一些不准确的内容,所谓的大模型“幻觉问题”,生成出错误信息。原因是它通过大量数据来学习,但这些数据并不总是绝对正确的。引入检索功能后,大模型可以利用这些外部的真实资料来避免“幻想”,尤其是在生成事实性知识时,检索的可靠性远胜于“凭空想象”。
最后,大模型的训练和运行非常耗费资源,而这些庞大的模型往往记忆了很多常识性知识。事实上,这些常识完全可以通过检索即时获取,而不必占用模型的宝贵资源。RAG为生成模型装上了一个“搜索引擎”,极大地减轻了其资源负担,就像我们不必记住所有事情,因为可以随时用搜索引擎查找一样。
归根结底,RAG为大模型提供了一个“得力助手”,让它不再需要事事亲力亲为,可以专注于推理和创新。这就像我们的大脑,利用工具来辅助记忆和查找信息,从而把精力集中在真正重要的思考和决策上。
参考文献:
[1] Li H, Su Y, Cai D, et al. A survey on retrieval-augmented text generation[J]. arXiv preprint arXiv:2202.01110, 2022.
[2] Lewis P, Perez E, Piktus A, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks[J]. Advances in Neural Information Processing Systems, 2020, 33: 9459-9474.
[3] Chen J, Lin H, Han X, et al. Benchmarking large language models in retrieval-augmented generation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2024, 38(16): 17754-17762.
[4] Zhao P, Zhang H, Yu Q, et al. Retrieval-augmented generation for ai-generated content: A survey[J]. arXiv preprint arXiv:2402.19473, 2024.
供稿:清华大学 王东
制作:北京邮电大学 戴维
审核:北京邮电大学 李蓝天