
第五篇 统计学习方法是如何实现分类与聚类的(一)
清华大学计算机系 马少平
艾博士导读
统计机器学习方法在人工智能发展历史上曾经起到过重要作用,当上个世纪90年代初期人工智能陷入低谷时,也正是统计机器学习的发展才使得人工智能走出了低谷,逐渐得到广泛的应用,当前的人工智能发展高潮应该与统计机器学习方法的发展紧密相关,虽然热潮来自于深度学习。即便在今天,统计机器学习方法也有着广泛的应用。
统计机器学习的最大特点是具有良好的理论基础,也可能正因为如此,本篇内容具有较多的公式,也打破了我在写作本书时定下的尽可能少用公式的禁忌,不过大家在学习本篇内容时,也不要被大量出现的公式所吓倒,我会尽可能说明每个公式的含义及来龙去脉,即便你没有弄清楚具体的推导过程,也可以了解其中的思想。
本篇主要介绍统计机器学习方法中几个典型的监督与非监督学习方法,按照难易程度可以划分为三个不同的等级,读者可以根据自身需要有选择的阅读其中几节或者全部内容。
第一级:5.1节,介绍统计机器学习的基本概念。5.3节中到5.3.1之前的部分,介绍决策树的基本概念。5.4节,介绍k近邻分类方法。5.5节中的5.5.1,介绍支持向量机的基本概念。5.6节开始部分,介绍聚类问题的基本概念。5.9节,介绍统计机器学习中的验证与测试方法,以及分类问题的评价指标。
第二级:5.2节,介绍朴素贝叶斯分类方法。5.3开始部分以及其中的5.3.1,介绍构建决策树的ID3方法。5.5节中的5.5.2,介绍线性可分支持向量机。5.6节介绍k均值聚类方法。5.7节介绍层次聚类方法。
第三级:5.3节中的5.3.2~5.3.4,介绍构建决策树的C4.5方法;介绍建造决策树过程中可能出现的过拟合问题,以及解决过拟合问题的剪枝方法;介绍什么是随机森林以及构建方法。5.5节中的5.5.3~5.5.6,介绍线性支持向量机以及非线性支持向量机;介绍求解非线性支持向量机的核方法;介绍如何用二分类支持向量机求解多分类问题。5.8节,介绍基于密度的聚类方法DBSCAN算法。5.10节,结合文本分类问题和脱机手写汉字识别问题,分别介绍两种抽取特征的方法。
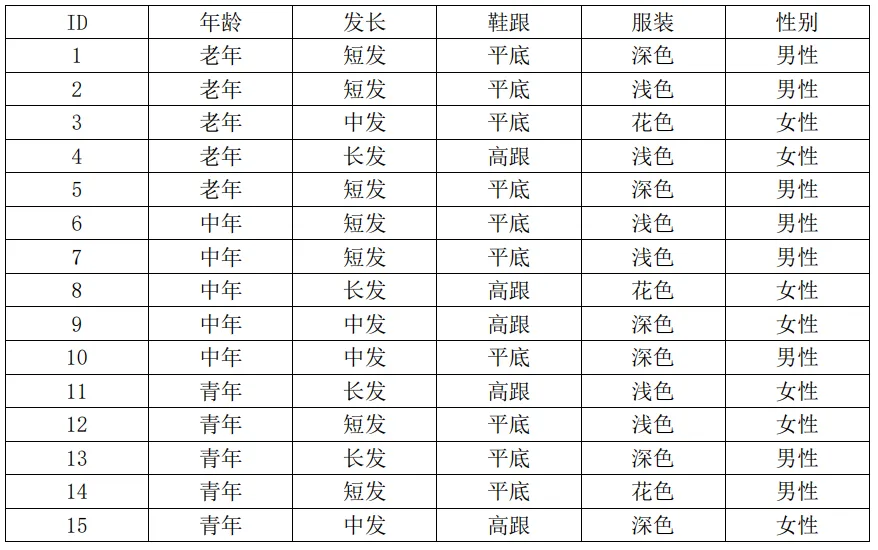
这天正在学习人工智能的小明,看到了这样一个题目。如表5.1所示,给出的是一个男女性别样本数据表。该表共有称作样本的15组数据,每组数据对应一个样本,每个样本有“年龄”、“发长”、“鞋跟”和“服装”等四种特征,最后一列给出了是“男性”或者“女性”的性别分类。其中年龄划分为老年、中年和青年,发长划分为短发、中发和长发,鞋跟划分为平底和高跟,服装划分为深色、浅色和花色,这些称为特征的取值。比如第一组数据,表示的是“一位老年人,留有短发,穿着平底鞋,身穿深色服装,其性别为男性”。而第三组数据,表示的是“一位老年人,头发中长,穿着平底鞋,身穿花色服装,其性别为女性”。题目要求根据这些样本数据能否建立一个人工智能系统,当任意输入一个人的“年龄”、“发长”、“鞋跟”和“服装”这四个特征的取值后,即便是表5.1中不存在的样本,系统也可以判断出该人的类别,即是男性还是女性。
小明第一次遇到这样的题目,思考了一会后也没有想到什么好的求解方法,又来请教艾博士。
表5.1 男女性别样本数据表
第一节:统计学习方法
了解了小明的来意之后,艾博士讲解起来:这个问题属于统计学习方法研究的范畴,我们先简单介绍一下什么是统计学习方法。
统计学习方法又称作统计机器学习方法,属于机器学习的一种。
小明:什么是机器学习呢?
艾博士:我们人之所以能做很多事情,重要的就是具有学习能力。我们从小到大一直在学习,通过学习提高我们做事情的能力。计算机也是一样,我们也希望计算机能像人一样,拥有学习能力,一旦拥有了这种学习能力,计算机就可以帮助人类做更多的事情。这也是人工智能所追求的目标。
著名学者司马贺(赫伯特·西蒙)教授曾经对机器学习给出过一个定义:“如果一个系统能够通过执行某个过程改进它的性能,这就是学习”。
小明:这和我们人类的学习也差不多,我们学习不就是提升自我做事的能力吗?
艾博士:统计机器学习就是计算机系统通过运用数据及统计方法提高系统性能的机器学习。其特点是运用统计方法,从数据出发提取数据的特征,抽象出问题的模型,发现数据中所隐含的知识,最终用得到的模型对新的数据进行分析和预测。
统计机器学习一般具有两个过程。一个过程是学习,又称作训练,是从数据抽象模型的过程。另一个过程是使用,用学习到的模型对数据进行分析和预测。为了实现第一个过程,一般需要一个供学习用的数据集,又称作训练集,由训练样本组成的集合,这是学习、训练的依据。
像小明刚刚提到的这个题目,表5.1给出的就是数据集,数据集中的每一个样本由若干特征和类别标签组成,其中的“年龄”、“发长”、“鞋跟”和“服装”就是特征,而性别就是类别标签。依据这个数据集采用某个统计学习方法建立一个男女性别分类模型,当任意给定一个人的“年龄”、“发长”、“鞋跟”和“服装”特征时,模型输出该人的性别。
当然这里只是给出了一个例子,对于实际问题来说,这个数据集太小了,需要更多的数据,特征数目也不够多,取值也需要再细化。
小明:统计机器学习都有哪些方法呢?
艾博士:统计机器学习具有很多种方法,从是否有类别标签的角度,可以划分为以下几种:
1、有监督学习
艾博士:有监督学习又称作监督学习、有教师学习,也就是说给定数据集中的样本具有类别标签。这就好比是小孩认识动物一样,看到了一只猫,妈妈告诉小孩这是一只猫,看到了一只狗,妈妈又告诉说这是一只狗,慢慢地小孩就学会了认识猫和狗。
小明:这里的“监督”指的就是类别标签吗?
艾博士肯定地说:是的,监督指的就是类别标签信息。这类任务为的是让人工智能系统学会认识某个事物属于哪个类别,也就是根据特征划分到指定类别,一般称作为分类。
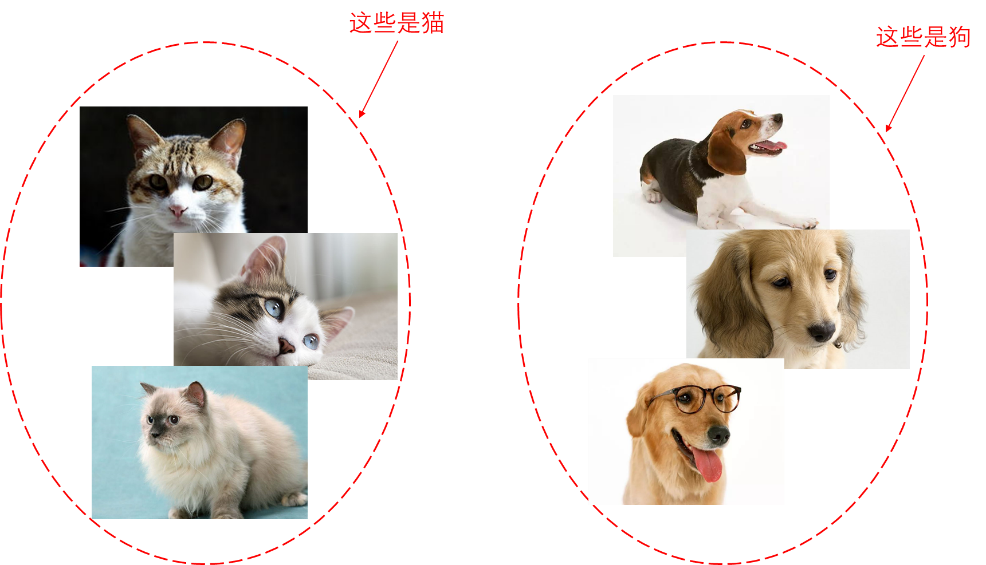
图5.1 监督学习示意图
2、无监督学习
艾博士:无监督学习又称作无教师学习,与监督学习刚好相反,给定的数据集中的样本只有特征没有类别标签。比如假设一个人从没有看到过狗和猫,给他一些猫和狗的照片,他虽然不认识哪个是猫哪个是狗,但是该人观看了一会照片后,根据两种动物的特点,他可以区分出这是两种不同的动物,进而可以将这些照片划分为两类:一类是狗,一类是猫,虽然他并不知道每一类是什么动物。
小明:由于没有标签信息,这类任务只能做到把类似的东西归纳为一个类别吧?
艾博士:确实如此,这类任务就是将特征比较接近的东西聚集为一类,一般称作聚类。
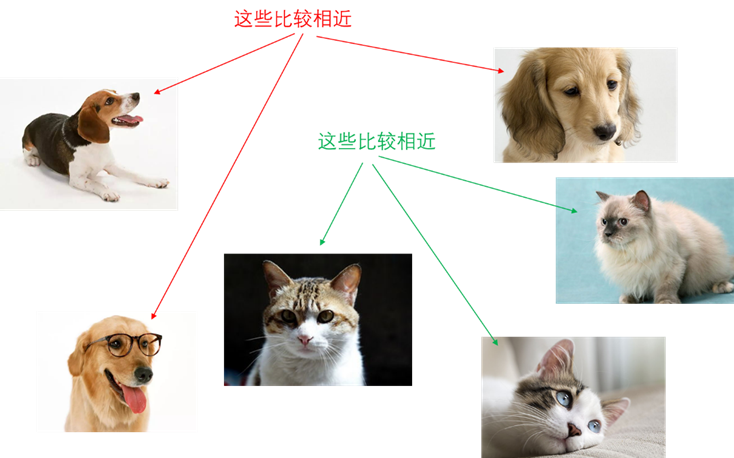
图5.2 无监督学习
3、半监督学习
艾博士:顾名思义,半监督学习就是数据集中有部分样本有标签信息,部分样本没有标签信息。半监督学习就是如何利用这些无标签数据,提高学习系统的性能。比如在一些猫和狗的照片中,一部分照片标注是猫或者是狗,但是也有一部分照片没有任何类别标注。
小明:如何利用无标签样本呢?
艾博士:一般来说,半监督学习中大部分样本还是有标签的,利用有标签样本可以大概预测出那些无标签样本的类别,利用预测结果可以进一步优化系统的分类性能。当然预测结果会存在一定的错误,这是半监督学习要解决的问题。
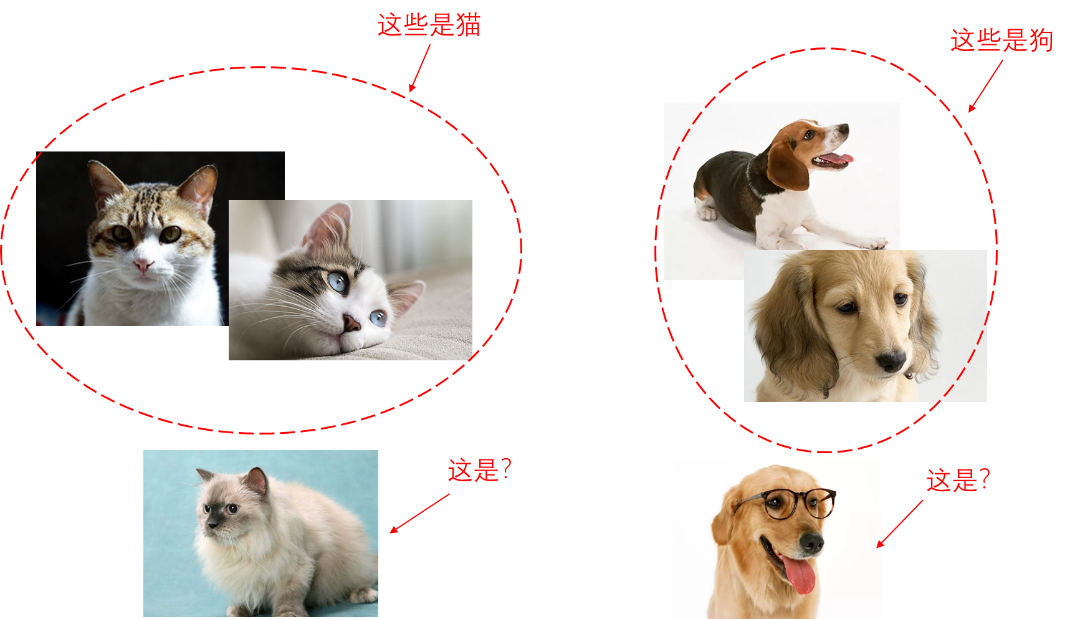
图5.3 半监督学习示意图
4、弱监督学习
艾博士:弱监督学习指的是提供的学习样本中标签信息比较弱,这又可以分为几种情况。第一种是标签信息不充分,只有少量样本具有类别标签,而大部分样本没有标签信息。
小明:这与半监督学习有什么区别呢?
艾博士:严格来说半监督学习可以归类到这类弱监督学习中,都属于不完全监督学习。但是一般情况下,半监督学习带标签样本会更多一些,而弱监督学习中的带标签样本会更少。

图5.4 弱监督学习——不完全监督学习
艾博士:第二种弱监督学习是不确切监督学习,其特点是具有类别标签信息,但是标注对象不明确,只给了一个粗粒度的标注。比如一张遛狗的照片,照片中有狗,也有人,也有其他的东西,标签只说明照片中有狗,但是没有明确地指名具体哪个是狗。
小明:感觉这类学习难度就更大了,因为虽然具有标签信息,但是属于粗粒度的标注,学习过程中需要明确具体的标注对象。
艾博士:是的,增加了不少学习难度。这类学习可以把样本想象成一个包,标签信息只说明了包内有什么,而没有说明包内的具体所指。

图5.5 弱监督学习——不确切监督学习
艾博士:还有一类弱监督学习就是强化学习。在强化学习中没有明确的数据告诉计算机学习什么,但是可以设置奖惩函数,当结果正确时获得奖励,而结果错误时遭受惩罚,通过不断试错的方法获得数据,从而进行学习。
小明:在第二篇中讲过的下围棋的AlphaGo就用到了强化学习吧?
艾博士:AlphaGo中用到了强化学习,而AlphaGo Zero则摆脱了人类数据,完全依靠强化学习达到了人类棋手所不能达到的下棋水平。
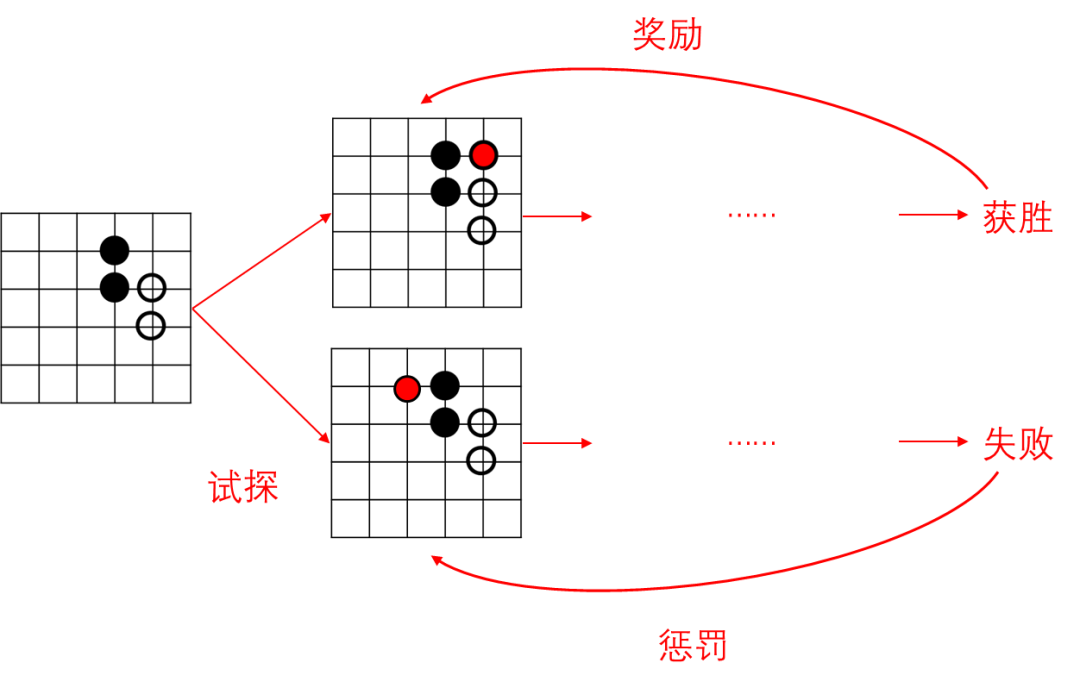
图5.6 弱监督学习——强化学习
除此之外,还有不精确监督学习也属于弱监督学习,其特点是标签信息存在错误标注,比如将个别狗的照片标记成了猫,或者将个别猫的照片标记成了狗。一般来说当数据集大了以后都不可避免地会存在一些标注错误,有些机器学习方法对少量标注错误并不敏感,有些方法可能比较敏感,即便存在少量错误标注的样本,也可能会带来比较大的问题,这就涉及如何剔除这些错误标注样本的问题。
以上从样本标签的角度对机器学习方法做了分类,每类还有不同的机器学习方法。下面几节中,我们将介绍其中几个典型的监督和非监督统计机器学习方法。
小明读书笔记
统计机器学习属于机器学习的一种,其特点是运用数学统计方法,抽象出问题的模型,发现数据中蕴含的内在规律,用得到的模型实现对新数据的分析和预测。
统计机器学习分为两个过程,一个是训练过程,从数据抽象模型的过程,一个是使用过程,用学习到的模型对数据进行分析和预测。为了实现训练过程,需要一个数据集,称作训练集,由训练用样本组成的集合,这是训练的依据。
按照是否有标注信息以及标注信息的多少,统计机器学习可以划分为有监督学习、无监督学习、半监督学习和弱监督学习等。
未完待续