生活中很多事情可以抽象成序列到序列的转换。例如,语言翻译是两种语言单词序列的转换,语音合成是单词序列到发音序列的转换,玩游戏是游戏画面到游戏杆操作命令的转换。
序列到序列转换相当困难,因为不仅要考虑两个序列间的对应关系,还要考虑目标序列的上下文相关性。以翻译任务为例,要翻译“How are you”,即要找到和每个单词对应的汉语词,比如“How”对应“怎样”,“You”对应“你”,也要考虑汉语的成句习惯,最后才能得到“你怎么样”这样正常的翻译。
传统序列到序列模型是基于“分析法”的,把源序列中的每个元素解析出来,再基于统计规则来确定最终得到的目标序列,典型的如条件随机场方法。
近年来,随着深度学习技术的兴起,基于神经网络的序列到序列模型得到广泛应用。如下图所示,这一模型分为编码器和解码器两部分,其中编码器用来将输入序列压缩成一个固定维度的向量,而解码器用来从这一向量中恢复出目标序列。
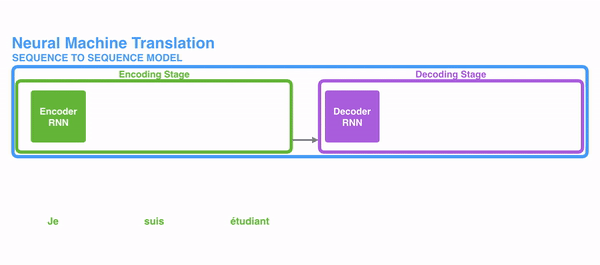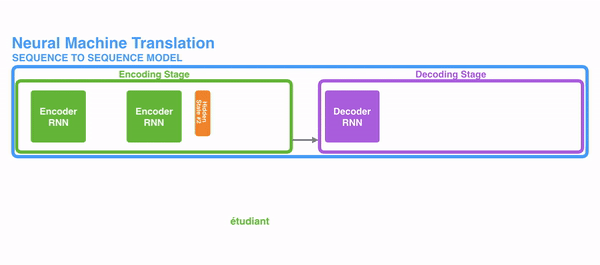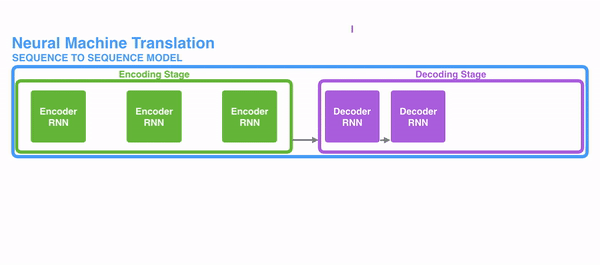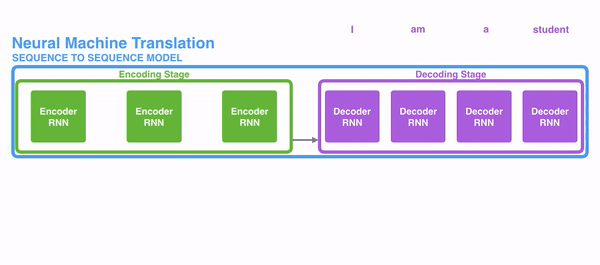
这个过程有点儿像俄罗斯套娃,编码器把一个个娃从小到大套在一起,而解码器再把这些娃一层层地剥掉。

为了描述时序相关信息,编码器和解码器一般都基于循环神经网络。这种网络的特点是具有记忆功能。因此,它既可以用在编码器里作为信息压缩的工具,也可以用在解码器里作为序列数据生成的工具。
序列到序列模型可以理解为一个人类翻译人员在听到一句英语时,首先进行理解,弄明白这句话的主要意思;基于这一理解,再按汉语的语言习惯来生成合理的汉语句子。序列到序列模型的一个重要特点是不再纠结序列中元素之间的具体对应,只需给出一个输入句子,就可以得到一个合理的目标句子。这一新的建模模式通常称为“端到端建模”。端到端模型极大简化了建模过程。同时,因为去掉了一些不必要的人为设计,当数据量足够大时,往往得到更好的性能。
By:清华大学 王东