
第一篇 神经网络是如何实现的(五)
清华大学计算机系 马少平
第五节:梯度消失问题
小明:艾博士,在这两个例子中,您均提到了用ReLU这个激活函数,这是为什么呢?
艾博士:你又提了一个好问题。小明,我先问你一个问题,在前面我们介绍的BP算法中,是如何更新权重值的?
小明:这个我还记得,更新公式为:
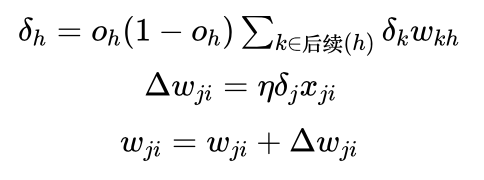
艾博士:小明你记得很清楚。BP算法中主要是根据后一层的 δ 值计算前一层的δ 值,一层一层反向传播。由 δ 的计算公式可以看到,每次都要乘一个 oh(1-oh) ,其中 oh 是神经元h的输出。当采用sigmoid激活函数时, 取值在0、1之间,无论 oh 接近1还是接近0,oh(1-oh) 的值都比较小,即便是最大值也只有0.25(当 时)。如果神经网络的层数比较多的话,反复乘以一个比较小的数,会造成靠近输入层的 oh 趋近于0,从而无法对权重进行更新,失去了训练的能力。这一现象称作梯度消失。而 oh(1-oh) 刚好是sigmoid函数的导数,所以用sigmoid激活函数的话,很容易造成梯度消失。而如果换成ReLU激活函数的话,由于ReLU(net)=max(0, net),当net>0时,ReLU的导数等于1, oh(1-οh) 这一项就可以用1代替了,从而减少了梯度消失现象的发生。当然,梯度消失并不完全是激活函数造成的,为了建造更多层的神经网络,研究者也提出了其他的一些减少梯度消失现象发生的方法。
小明:都有哪些方法,能否再举几个例子呢?
艾博士:好的,我们再举两个比较典型的例子。
第一个例子是GoogLeNet,该神经网络在ImageNet比赛中曾经获得第一名。
小明看着GoogLeNet这个名字有些奇怪,问艾博士:这里的“L”为什么是大写呢?是不是写错了?
艾博士说:没有写错,这里用的就是大写的L。前面咱们介绍过一个早期的识别手写数字的神经网络LeNet,可以说是最早的达到了实用水平的神经网络,所以GoogLeNet在命名时有意将L大写(后边5个字符刚好是LeNet),以示该网络是在LeNet的基础上发展而来。
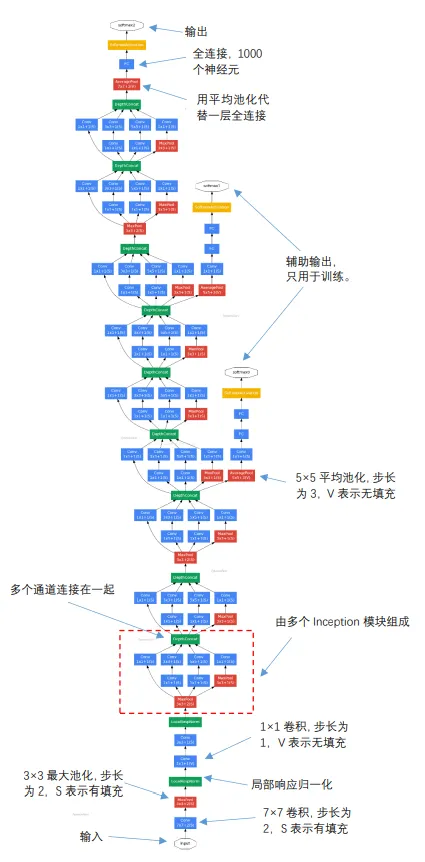
图1.29 GoogLeNet示意图
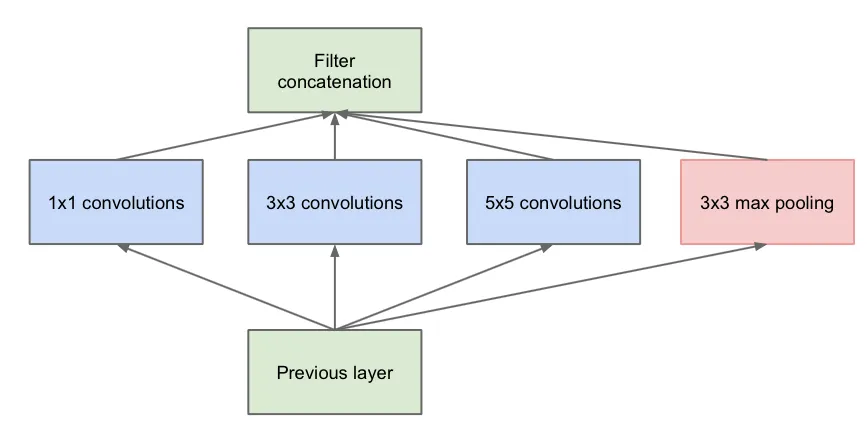
图1.30 原始的inception模块
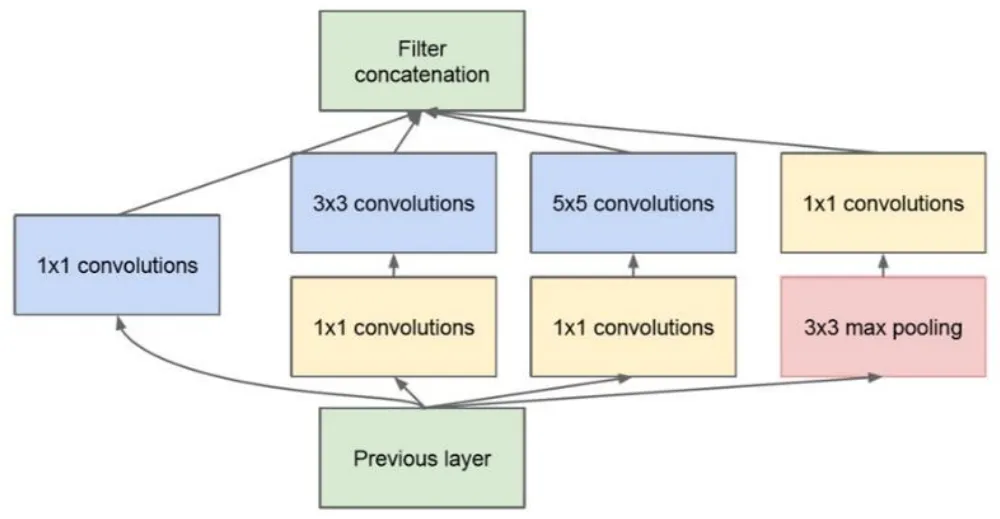
图1.31带降维的inception模块
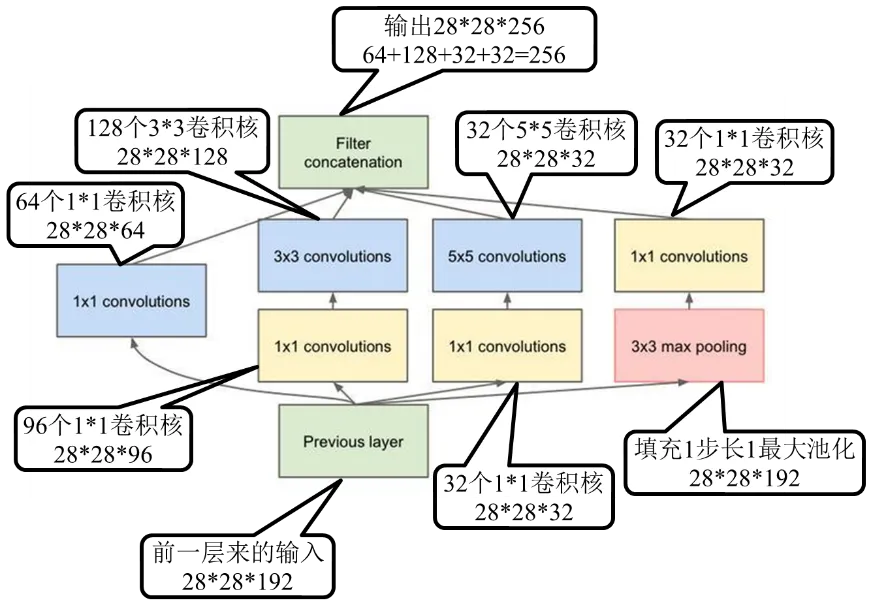
图1.32 GoogLeNet第一个inception模块
GoogLeNet有些复杂,其结构如图1.29所示,输入层在最下边。该网络有两个主要特点,第一个特点与解决梯度消失问题有关。
不同于一般的神经网络只有一个输出层,GoogLeNet分别在不同的深度位置设置了3个输出,图中用黄颜色表示,分别命名为softmax0、softmax1和softmax2,从名称就可以看出,3个输出均采用了softmax激活函数。对三个输出分别构造损失函数,再通过加权和整合在一起作为总体的损失函数。这样三个处于不同深度的输出,分别反向传播梯度值,同时配合使用ReLU激活函数,就比较好地解决了梯度消失问题。
小明:这个神经网络有3个输出,训练好后如何使用呢?
艾博士:三个输出中,最上边的softmax2是真正的输出,另外两个是辅助输出,只用于训练,训练完成后,就不再使用了。
小明:这种方式解决梯度消失问题确实有点巧妙。
艾博士:小明,GoogLeNet的第二个特点是整个网络由9个称作inception的模块组成,图1.29中虚线框出来的部分就是第一个inception模块,后面还有8个这样的模块。
小明:艾博士,这个inception模块是什么意思呢?
艾博士:我们先从最原始的inception讲起,如图1.30所示的就是一个原始的inception模块,它由横向的4部分组成,从左到右分别是1×1卷积、3×3卷积和5×5卷积,最右边还有一个3×3的最大池化。每种卷积都有多个卷积核,假定1×1卷积有a个卷积核,3×3卷积有b个卷积核,5×5卷积有c个卷积核,那么这三个卷积得到的通道数就分别为a、b、c个,最右边的3×3最大池化得到的通道数与输入一致,假设为d。将这4部分得到的通道再并排在一起,则每个inception的输出共有a+b+c+d个通道。
小明看着原始inception模块的示意图问艾博士:这里为什么用不同大小的卷积核呢?以前介绍的卷积神经网络,同一层用的都是大小相同的卷积核。
艾博士回答说:这也是GoogLeNet的创新之一。我们介绍过,不同大小的卷积核可以抽取不同粒度的特征,GoogLeNet通过inception在每一层都抽取不同粒度的特征再聚合在一起,达到更充分利用不同粒度特征的目的。
小明:我明白了原始inception模块的作用,是不是还有改进型的inception模块啊?
艾博士:是的,目前对inception模块有很多种改进,我们下面介绍一个比较典型的改进。其基本思想是引入了“网中网”的概念,主要目的是为了减少神经网络的参数量,也就是权重的数量,从而提高训练速度。图1.31给出的就是一个带降维的inception模块示意图,与原始的模块相比较,主要是引入了3个1×1卷积,两个分别放在了3×3卷积和5×5卷积的前面,一个放在了最右边3×3最大池化的后边。
小明:艾博士,为什么引入1×1卷积的呢?
艾博士回答说:引入1×1卷积有两个作用。第一,1×1卷积核由于还有个厚度,相当于在每个通道上的相同位置各选取一个点进行计算,每个点代表了某种模式特征,不同通道代表不同特征,所以其结果就相当于对同一位置的不同特征进行了一次特征组合。第二,就是用1×1卷积对输入输出的通道数做变换,减少通道数或者增多通道数,如果输出的通道数少于输入的通道数,就相当于进行降维,反之则是升维。比如输入是100个通道,如果用了60个1×1的卷积核,则输出具有60个通道,通道数减少了40%,就实现了降维操作。在inception中增加的3个1×1卷积,都是为了降维的,所以这种模块被称为带降维的inception模块。
小明不太明白地问道:降维后带来了什么好处呢?
艾博士说:小明你计算一下,假设inception的输入有192个通道,使用32个5×5的卷积核,那么共有多少个参数呢?
小明认真地计算起来:由于输入是192个通道,则一个卷积核有5×5×192+1个参数,其中的1是偏置b。一共32个卷积核,则全部参数共有(5×5×192+1)×32=153632个。
艾博士看着小明的计算说:如果在5×5卷积前增加一层具有32个卷积核的1×1的卷积的话,则总参数又是多少个呢?
小明又埋头计算起来:1×1卷积的输入是192个通道,则一个卷积核的参数个数为1×1×192+1,共32个卷积核,则参数共有(1×1×192+1)×32=6176个。1×1的卷积输出有32个通道,输入到32个卷积核的5×5卷积层,这层的参数总数为(5×5×32+1)×32=25632个。两层加在一起共有6176+25632=31808个参数。
艾博士:小明你看,在没有降维前参数共有153632个,降维后的参数量只有31808个,只占降维前参数量的20%左右,可见降维的作用明显。
小明又指着图1.31右边问道:艾博士,这里在最大池化后面加入1×1卷积层又是为了什么呢?
艾博士回答说:这里就纯粹是为了降维了,因为输入的通道数可能比较多,用1×1卷积把通道数降下来。
图1.32给出了GoogLeNet中第一个inception模块采用的卷积核数,我就不具体讲了,小明你自己看就可以了。
小明:好的,我自己课后仔细对照着看看。艾博士,除了介绍的两个特点外,GoogLeNet还有哪些特点呢?
艾博士:还用了一些小技巧。在靠近输出层用了一层7×7的平均池化,这一层一般是个全连接层,在GoogLeNet中用平均池化代替了一个全连接层。由于池化是作用在单个通道上的,而每个通道抽取的是相同模式的特征,所以平均池化反映了该通道特征的平均分布情况,起到了对特征的平滑作用。据GoogLeNet的提出者介绍说,这样不仅减少了参数量,还可以提高性能。另外就是在第一个inception之前分别加入了两层局部响应归一化,在适当的地方加入归一化层是一种常用的手段,其目的是为了防止数据的分布不要产生太大的变化,因为神经网络在训练过程中每一层的参数都在更新,如果前面一层的参数分布发生了变化,那么下一层的数据分布也会随之变化,归一化的作用就是防止这种变化不要太大。除了局部响应归一化外,现在用的更多的是批量归一化。具体的归一化方法我们就不介绍了,有兴趣的话,可以参阅有关文献。
小明听了艾博士的讲解,又很好奇地问道:艾博士,GoogLeNet中的模块为什么叫inception呢?
艾博士解释说:inception一词来源于电影《盗梦空间》的英文名,如图1.33所示。电影中有一句对话:We need to go deeper(我们需要更加深入),讲述的就是如何在某人大脑中植入思想,寓意进行更深刻的感知。这些年来,神经网络一直在向更深的方向发展,层数越来越多,“更加深入”也正是神经网络研究者所希望的,所以就以inception作为了模块名。
小明:好有意思,原来还跟电影有关。为什么神经网络需要更多的层数呢?

图1.33 电影《盗梦空间》
艾博士说:原则上来说,神经网络越深其性能应该越好,假设已经有了一个k层的神经网络,如果在其基础上再增加一层变成k+1层后,由于又增加了新的学习参数,k+1层的神经网络性能应该不会比原来k层的差。但是如何建造更深的网络并不是那么容易,往往简单地增加层数效果并不理想,甚至会更差。所以,我们虽然希望构建更深层的神经网络,但由于有梯度消失等问题,深层神经网络训练会更加困难。虽然有些方法可以减弱梯度消失的影响,但当网络达到一定深度后,这一问题还是会出现。实验结果表明,随着神经网络层数的增加,还会发生退化现象,当网络达到一定深度后,即便在训练集上,简单地增加网络层数,损失函数值不但不会减少,反而会增加。图1.34给出了这样的例子。
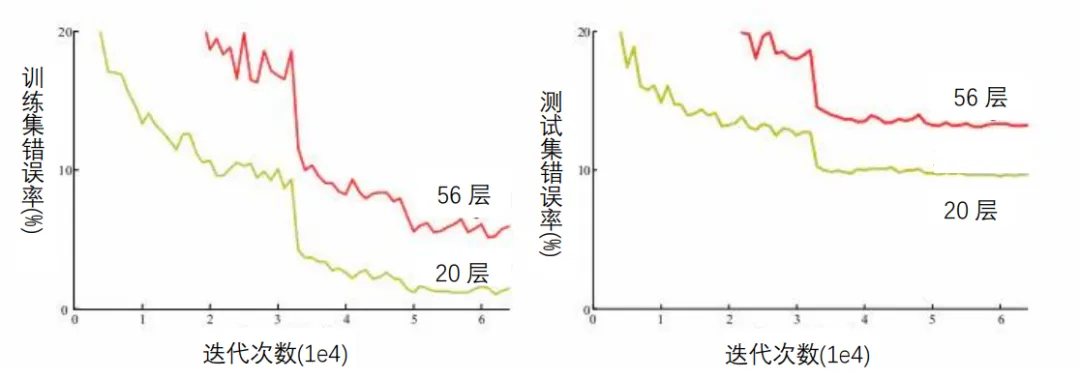
图1.34 普通神经网络不同深度时的错误率
在图1.34中,横坐标是训练的迭代次数,纵坐标是错误率,其中左边是在训练集上的错误率,右边是在测试集上的错误率。从图中可以看出,无论是在训练集上还是在测试集上,56层神经网络的错误率都高于20层神经网络的错误率。
小明惊愕地问道:这是为什么呢?
艾博士回答说:这个问题比较复杂,并不是单纯是因为梯度消失问题造成的。原因可能有很多,还有待于从理论上进行分析和解释。这个例子说明,虽然神经网络加深后原则上效果应该会更好,但是并不是简单地加深网络就可以的,必须有新的思路解决网络加深后所带来的问题。
小明不等艾博士说完急着问道:有什么好方法吗?
艾博士说:残差网络(ResNet)就是解决方案之一。残差网络在GoogLeNet之后,曾经以3.57%的错误率获得ImageNet比赛的第一名,首次达到了低于人类错误率的水平。
图1.35给出了一个34层的残差网络示意图,而参加ImageNet比赛的残差网络,达到了152层。图中最上面是神经网络的输入层,最下边是输出层。
小明:残差网络是如何做到这么深的网络的呢?
艾博士:残差网络主要由多个如图1.36所示的残差模块堆砌而成。一个残差模块含有两个卷积层,第一层卷积后面接一个ReLU激活函数,第二层卷积不直接连接激活函数,其输出与一个恒等映射相加后再接ReLU激活函数,作为残差模块的输出。这里的恒等映射其实就是把残差模块的输入直接“引”过来,与两个卷积层的输出相加。这里的“相加”指的是“按位相加”,即对应通道、对应位置进行相加,显然这要求输入的通道数和通道的大小与两层卷积后的输出完全一致。如果残差模块的输入用X表示(X表示具有一定大小的多通道输入),两层卷积输出用F(X)表示,则残差模块的输出 F'(X) 为:
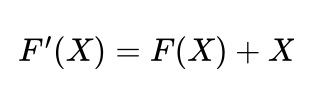
小明对比着残差网络和残差模块示意图,有些疑惑地问到:这里的恒等映射看起来有些奇怪,感觉像电路中“短路”一样,为什么要这样设计呢?
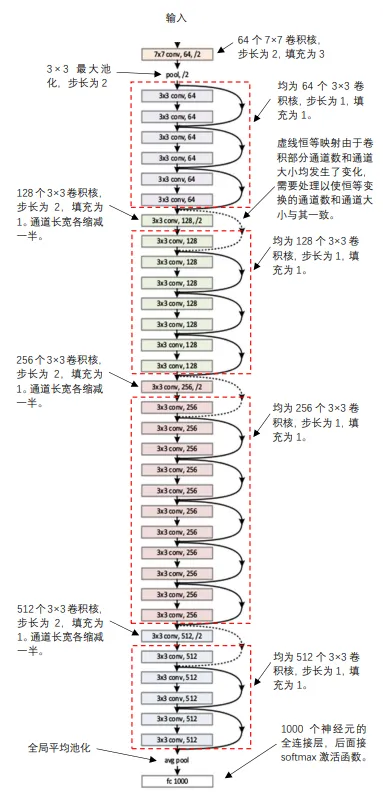
图1.35残差网络示意图
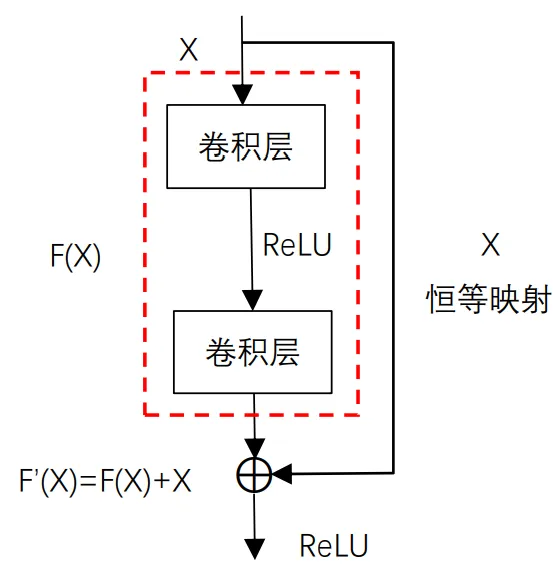
图1.36 残差模块示意图
艾博士回答说:这是一个非常巧妙的设计。其一,通过“短路”,可以将梯度几乎无衰减地反传到任意一个残差模块,消除梯度消失带来的不利影响。其二,前面我们说过,由于存在退化现象,在一个k层神经网络基础上增加一层变成k+1层后,神经网络的性能不但不能提高,还可能会下降。残差网络的设计思路是,通过增加残差模块提高神经网络的深度。由于残差模块存在一个恒等映射,会把前面k层神经网络的输出直接“引用”过来,而残差模块中的F(X)部分相当于起到一个“补充”的作用,弥补前面k层神经网络不足的部分,二者加起来作为输出。这样既很好地保留了前面k层神经网络的信息,又通过新增加的残差模块提供了新的补充信息,有利于提高神经网络的性能。可以说残差网络通过引入残差模块,同时解决了梯度消失和网络退化现象,可谓是一箭双雕。
小明问道:这真是一个非常巧妙的设计,但是为什么叫残差网络呢?
艾博士解释说:因为在残差模块中恒等部分是没有学习参数的,只有F(X)部分有需要学习的参数,如果把 看做是一个理想的结果的话, 就相当于是对误差的估计,残差网络通过一层层增加残差模块,逐步减少估计误差,所以取名残差网络。
小明醒悟道:原来是这样啊,这样就可以任意加深神经网络了吧?
艾博士说:也不尽然,神经网络是个比较复杂的系统,还有很多问题没有研究透。残差网络也不是可以无限制地添加残差模块。有实验表明,当网络深度增加到1000多层时,性能也会出现下降的现象,虽然下降的并不明显。
小明又指着图1.35所示的残差网络问艾博士:这个图中有3个残差模块的恒等映射画成了虚线,与实线有什么不同呢?
艾博士解释说:小明你观察的真仔细!这3处虚线确实与其他的恒等映射有所不同。画实线的恒等映射将前面残差模块的输出直接引用过来,是货真价实的恒等映射,而画虚线的恒等映射是需要做一些变换的。
小明问:这是为什么呢?
艾博士回答说:前面我们讲过,残差模块的输出是恒等映射和2个卷积层的输出按位相加后再连接激活函数,按位相加就必须通道数一样、通道的大小也一样。而在画虚线的残差模块中,第一个卷积核的步长是2,使得通道大小的宽和高各缩减了一半,另外卷积核的个数与输入的通道数也不一样了,这样就造成了在该残差模块的卷积层输出不能与恒等映射的输出直接相加了。为此需要对恒等映射进行改造,使得其输出的通道数和通道大小与卷积层的输出一致。怎么改造呢?一种简单的办法就是在恒等映射时加上一个1×1的卷积层,其步长和卷积核数与卷积层一致,以便二者可以直接按位相加。
艾博士又补充说:还有一点需要说明一下,图1.35所示的残差网络中,同GoogLeNet一样,在输出层的前面用一个平均池化代替一个全连接层,但是这里用的是一个全局平均池化。
小明问道:什么是全局平均池化呢?
艾博士反问道:小明,你还记得GoogLeNet中用的是多大的平均池化?
小明想了想回答道:我记得是7×7的平均池化。
艾博士称赞道:小明你记得很对。残差网络中用的也是平均池化,但是其大小刚好与输入的通道大小一样,也就是说,经过全局平均池化后,每个通道就变成了只有一个平均数,或者说,通道的大小变成1×1了。这相当于用一个具有代表性的平均值代替了一个通道,其效果不仅有效减少了要学习的参数个数,还可以提高神经网络的性能。
小明赞叹道:神经网络的设计中真是充满了各种小技巧啊。
小明读书笔记
BP算法是通过反向传播方法一层一层由输出层向输入层将梯度反传到神经网络的每一层的,在神经网络层数比较多的情况下,梯度值可能会逐步衰减趋近于0,从而造成距离输入层比较近的神经元的权重无法修正,达不到训练的目的。这种现象称为梯度消失问题。
为了消除梯度消失问题带来的影响,提出了一些解决方法。
当激活函数采用sigmoid函数时这种现象尤为严重,因为在BP算法中每次传播都要乘一个激活函数的导数,而sigmoid函数的导数值一般比较小,更容易造成梯度消失问题。用ReLU激活函数代替sigmoid函数是一种消除梯度消失问题的有效手段,因为ReLU函数当输入大于0时,其导数值为1,不会由于在反传过程中乘以激活函数的导数而导致梯度消失。这也是这些年来ReLU激活函数被广泛使用的原因之一。
在GoogLeNet中,为了解决梯度消失问题,除了使用ReLU激活函数外,还在神经网络的不同位置设置了3个输出,损失函数将三部分综合在一起,减少了梯度消失问题带来的不良影响。GoogLeNet由多个inception模块串联组成,每个inception模块中采用了不同大小的卷积核,将不同粒度的特征综合在一起。同时采用1×1卷积核做信息压缩,有效减少了训练参数,加快了训练速度。
原则上来说,神经网络越深其性能应该越好,但是一些实验表明,当网络加深到一定程度之后,即便是在训练集上也会出现随着网络加深而性能下降的现象,这一现象称为网络退化。这是个比较复杂的问题,并不是单纯的梯度消失造成的,还有待于从理论上进行分析和解释。
为解决网络退化问题,提出了残差网络ResNet。残差网络由多个残差模块串联而成,每个残差模块含有两个卷积层,并通过一个恒等映射和卷积层的输出按位相加在一起。从消除梯度消失的角度来说,残差网络由于恒等映射的存在,可以将梯度传递到任意一个残差模块;从消除网络退化的角度来说,残差网络由于恒等映射的存在,每增加一个残差模块都会把前面的神经网络输出直接“引用”过来,而残差模块中的F(X)部分相当于起到一个“补充”的作用,弥补前面神经网络不足的部分,二者加起来作为输出,这样既很好地保留了前面神经网络的信息,又通过新增加的残差模块提供了新的补充信息,有利于提高神经网络的性能。
未完待续