在第117期中,我们了解到自编码器是一种两头宽中间窄,形状如哑铃的神经网络。这一网络的学习目标是在输出端还原输入数据,如图1所示。由于网络中间的瓶颈层比较窄,使得仅有那些最重要的信息才会在编码z中保留下来。因此,自编码器常用于提取数据中的关键信息。
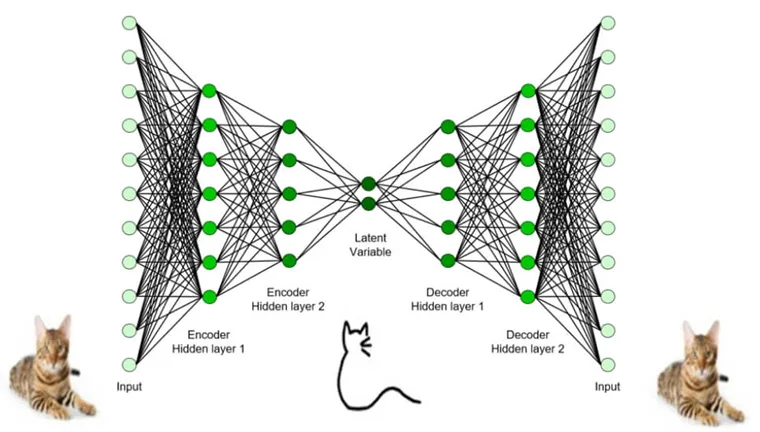
图1. 自编码器
事实上,瓶颈层的编码z由于维度较低,可视为处于原始数据的一个低维子空间,如图2所示。在这个子空间中,仅保留了那些最重要的信息,例如数字的类别、方向、笔迹粗细等,而对于那些不是那么重要的信息,比如每个像素点的灰度值,则被忽略。这个低维子空间通常被称为“流形”。假设我们在这个流形上改变z的值,就可以改变图片的属性。
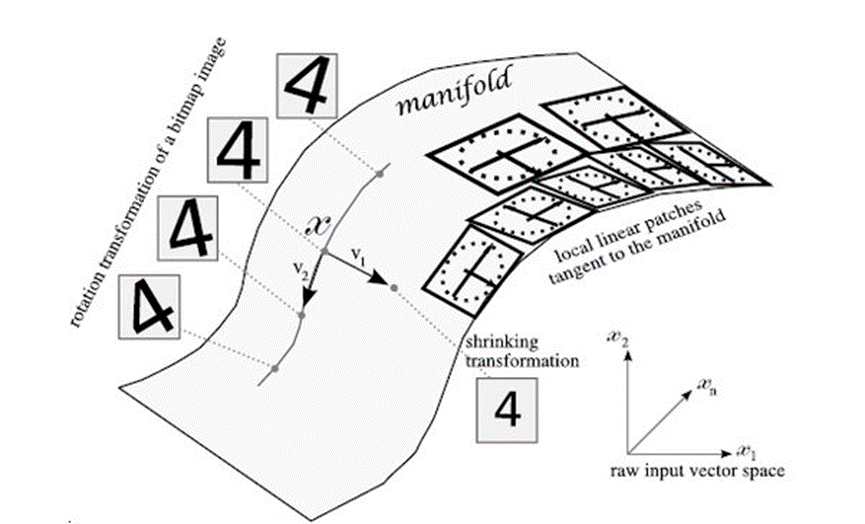
图2. 自编码器的流形空间[1]
现在的问题是,这个流形的空间是无限大的,那些真实数据所对应的位置既不规律又不聚堆,这使得子空间的操作变得非常困难。
一种解决方法是在训练时对z进行约束,使它符合某个简单的分布p(z),例如标准高斯分布N(0,1)。有了这个约束,z所处的位置就基本确定了。这样的模型称为变分自编码器 (VAE),如图3所示。
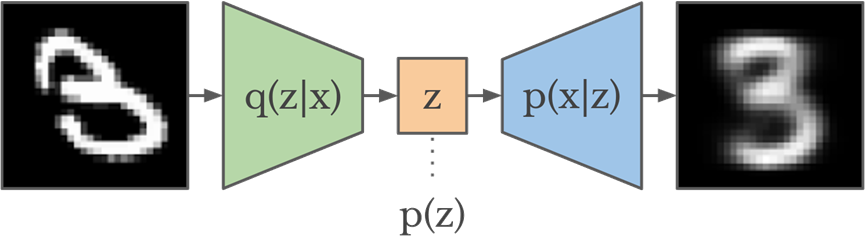
图3. 变分自编码器 (VAE)
变分自编码器[2]可以用作生成模型。这是因为模型训练完成后,所有真实数据的编码z都符合既定的分布p(z)。因此,如果我们从p(z)中随机选出一个点,经过解码器后就可以生成真实的图片。DeepMind的研究者发现,利用变分自编码器模型可以生成非常真实的图片,如图4所示。

图4. 由变分自编码器生成的人脸照片[3]
同时,我们也可以在z空间中进行游走,从而得到连续变化的图片,如图5所示。

图5. 由变分自编码器生成的连续变化数字图片[4]
总结起来,变分自编码器继承了传统自编码器的哑铃结构,但对瓶颈编码z进行了约束,使其符合特定的分布。有了这个约束,我们就可以对编码进行随机采样、生成和修改,从而得到各种有趣的生成效果。
参考文献:
[1] https://www.deeplearningbook.org/
[2] Kingma D P, Welling M. Auto-encoding variational bayes[J]. arXiv preprint arXiv:1312.6114, 2013.
[3] Razavi A, Van den Oord A, Vinyals O. Generating diverse high-fidelity images with vq-vae-2[J]. Advances in neural information processing systems, 2019, 32.
http://www.gwylab.com/pdf/vqvae2.pdf
[4] https://ml-showcase.paperspace.com/projects/variational-autoencoder-vae
By:清华大学 王东