大模型的火爆始于OpenAI推出的ChatGPT,自此之后,众多公司相继推出了自己的大模型。所谓大模型,就是那些通过海量数据训练出来的巨型语言模型。这些模型得益于深度神经网络强大的数据处理和建模能力,能够处理上百个TB的文本数据——相当于家用电脑硬盘容量的上百倍,基本上把人类的主要知识领域都学了个遍。这种庞大的语言模型不仅能理解人类的语言,还能以人性化的方式与人交流,甚至还可以完成写作文、写小说等创作行为。
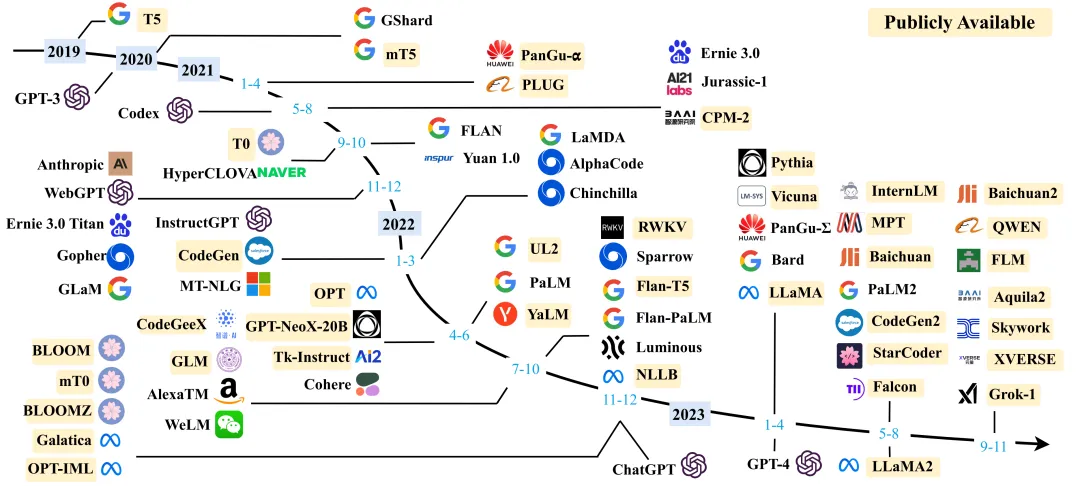
大语言模型的发展之路[1]
然而,大模型的胡说八道也是出了名的,而且每次胡说往往都表现得信心十足,引经据典。
比如,当让它介绍清华大学计算机系的马少平教授时,结果没有一句是真实的,全都是编造的。

当再请它列出马少平教授的代表作时,它不仅张冠李戴,把其他人的论文挪过来,甚至还自己捏造出一些压根不存在的文章。

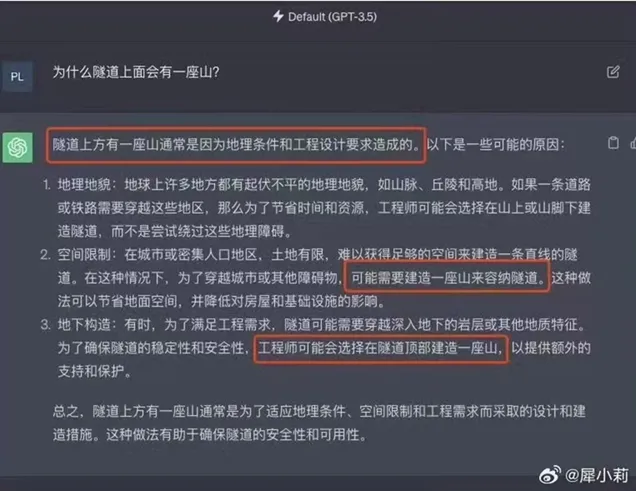
再举个例子,当问及ChatGPT这样的问题:“为什么隧道上面会有一座山?”它会信誓旦旦地说:“由于空间限制,可能需要建造一座山来容纳隧道。”它的回答显然是荒谬的,让人哭笑不得。
人们已经对大模型进行了大量研究,也提出了一系列解决方案,特别是加入了人类价值观的强化学习,至少让它不要超出底线。但即便如此,一些问题仍然难以完全避免,主要是因为大模型实在是太大了。以讯飞星火2.0为例,它的参数量达到1750亿个。
这个数字是什么概念呢?如果我们的屏幕每秒能打印10个参数,那么把这些参数全部打出来需要554年。
那么,这么多参数是如何确定的呢?它们是通过学习逐渐更新得到的,而学习目标是生成更像人类语言的句子。但问题是,即便机器学习得再好,我们也不知道它是如何达成这一目标的,也就不知道该如何控制它。这就是像老师教小朋友写作文,虽然可以看到小朋友的作文成果,却无法知道他们是怎么把这些词句想出来的。
目前,我们只能尽量把那些不容许出现的内容告诉机器,并引导它和我们在同一频道上思考。然而,人类的价值观本身就是多元化的,不同人对同一件事儿的认知可能差别很大,甚至完全相反。因此,让机器学会如此复杂的事情也确实不容易。所以,我们应对当前尚不完美的人工智能持宽容态度,给予它更多的发展时间。与此同时,我们也要时刻保持警惕,因为那些看似一本正经的句子中指不定哪句就是胡说的。
参考文献:
[1] Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., ... & Wen, J. R. (2023). A survey of large language models. arXiv preprint arXiv:2303.18223.
https://arxiv.org/pdf/2303.18223.pdf
By:清华大学 王东