当我们提到同卵双胞胎时,我们通常会想到他们在外貌上的惊人相似。然而,他们的相似性不仅仅局限于外表,他们的声音通常也极为相近。这种现象背后的原因在于,人类的发声特征受到遗传因素和生理结构的影响,而这些在同卵双胞胎中都是极为相似的。

图1. AI生成的“声音克隆”图片
想象一下,如果我们可以用科技手段创造一个“声音的双胞胎”,即使我们并不是真正意义上的双胞胎,也可以拥有一个几乎与自己声音相同的副本。这正是声音克隆技术所做的事情。
图2. 来自 Speaking AI 公司的声音克隆样例[1]
声音克隆技术通过捕捉我们说话的特点,比如音调、节奏和口音;然后利用这些信息来训练一个会说话的模型,使它能够模仿我们的声音。这就像是在数字世界中制造了一个我们的声音“克隆体”。当这个模型说话时,它的声音听起来就像是我们自己在说话一样。
在这一领域中,微软公司开发的 VALL-E 模型堪称是一项革命性的成就[2]。它采用深度学习技术中的 Transformer 模型架构,对目标人的声音进行精准且细致的分析和学习。总体上看,VALL-E 采用的是一种先进的神经编码器-解码器架构。这种架构首先通过编码器分析输入的语音样本,提取关键的声学特征,然后解码器基于这些特征生成新的语音输出。这种方法使得模型能够有效地捕捉和再现说话者的独特声音特征。
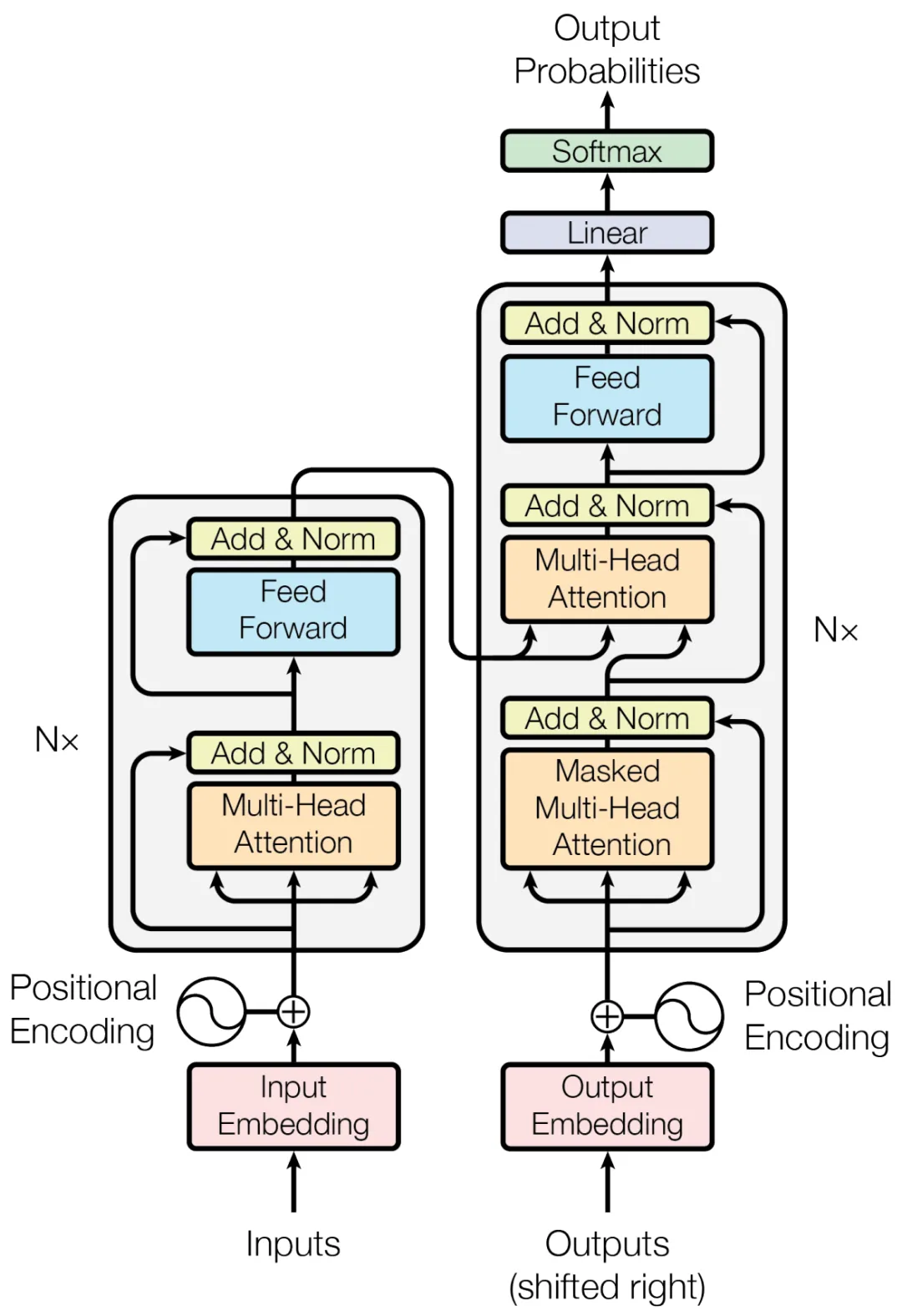
图3. Transformer 模型架构
在训练过程时,VALL-E 首先使用大量语音数据进行预训练,从而掌握语音的基本特征和结构;然后模型通过少量特定人的语音样本进行微调,使其学会模仿该人的特定声音特征。
VALL-E 在处理语音时,它不仅仅是复制语音中的那些基本特征,如基频、音调等,而是在更细致的层面上模仿说话者的声音特征,包括语调、语速、停顿、情感和口音等。这使得生成的语音不仅在听感上更像是特定人说的,而且在情感表达上也更加真实逼真。更牛的是,VALL-E 能够仅通过分析短短3秒的语音样本,就可以生成与目标人声音非常相似的合成语音。这些能力的实现,标志着声音克隆技术在模仿精准度和效率方面的重大进步。
当前,声音克隆技术在社会、文化和个人生活等众多领域展现出巨大的潜力,产生了许多积极贡献。例如,它能帮助那些因疾病或事故而失去语言能力的人重获自己的声音,通过克隆他们过去的语音记录,他们可以继续以自己的声音进行交流。再比如,声音克隆技术还可以被用来保存和重现历史人物的声音,为历史教育和文化展示增添生动性和真实感。比如,博物馆和教育机构可以利用这项技术来再现历史人物的演讲或对话。

图4. 小爱同学,定制声音
然而,尽管声音克隆技术拥有广泛的应用前景,但也伴随着滥用和诈骗的风险。例如,诈骗者利用声音克隆技术,模仿了你朋友的声音,骗取你相信他真的是你的朋友,导致非法的金钱诈骗。近年来,因声音克隆技术引发的诈骗案件屡见不鲜,值得我们深思。
因此,随着声音克隆技术的发展,对其合理运用和规范管理变得至关重要。在享受技术带来的便利的同时,我们也应时刻警惕,保护好自己的信息安全,确保这项技术能够在正道上发挥其应有的价值。
参考文献:
[1] https://speaking.ai/
[2] Wang C, Chen S, Wu Y, et al. Neural codec language models are zero-shot text to speech synthesizers[J]. arXiv preprint arXiv:2301.02111, 2023.
供稿:北京邮电大学 李蓝天
制作:北京邮电大学 戴维