深度神经网络很难训练,一个重要的原因是网络包含很多参数,这些参数互相影响,很难协调一致地往最优化方向调整。为此,研究者提出了很多方法,如预训练,激发值正规化等。基于这些方法,训练个十几层的网络是没有问题的。然而,一个很重要的问题是,神经网络是不是越深越好呢?
人们发现并不是。如图所示,训练两个网络,一个20层,一个56层,结果56层的训练误差比20层的还要大,意味着更深的模型反而学的更差。
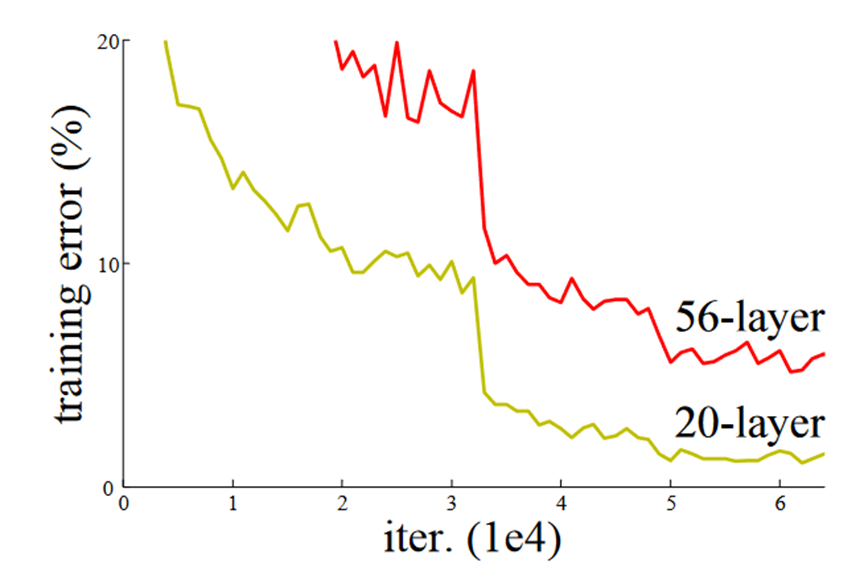
这是个让人很忧伤的结果。一个本来学习不错的少年,本想报个课外班加把劲,结果成绩反而下降了。另一个棘手的问题是,如果神经网络不是越深越好,那究竟多深才合适呢?难道要凭经验试?
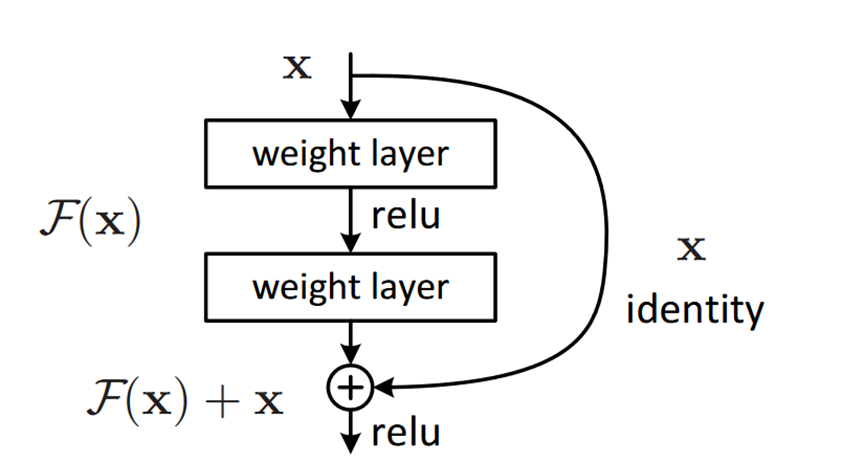
幸好,微软的科学家们在2015年提出了一种非常简洁的办法解决了这个问题[1]。他们设计了一种称为“残差学习”的思路。如图所示,他们在网络中加入了一个跨层连接。有了这个连接,如果原来的输入是X,学习目标是Y,现在只要学习目标Y-X就可以了,换句话说,是二者相对增量部分,即二者之间的“残差”。显然,学习残差要容易的多。
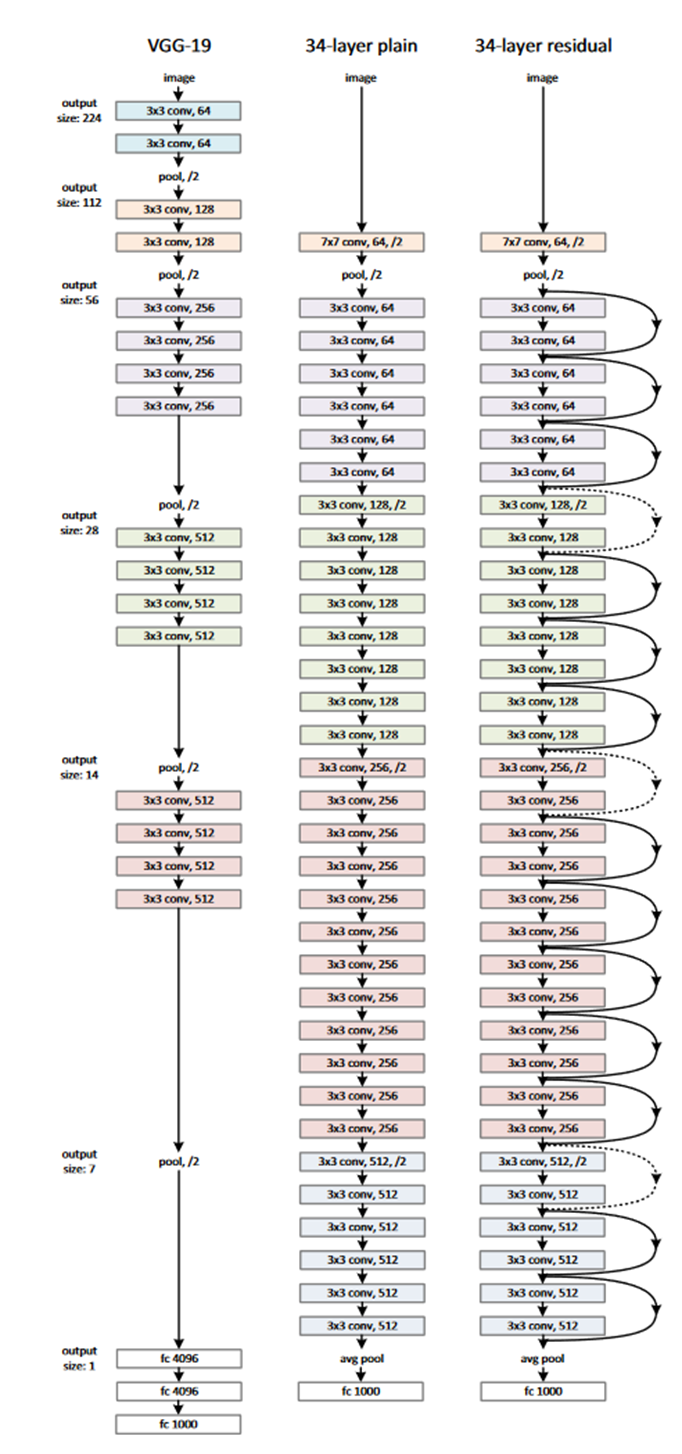
科学家们发现,有了残差学习再也不怕网络过深的问题了。他们构造了一个152层的残差网络在2015年ImageNet分类竞赛中斩获冠军,比当时主流的VGG网络深了8倍,计算复杂度却下降了。最重要的是,加深网络层数最多没有效果,却不会有负面影响了。加了一个跨层连接就解决了这么复杂的事情,这可能是机器学习中最富美感的设计之一。从此以后,残差连接成为深度神经网络的基本配置,为深度学习的进一步发展打下了基础。
参考文献:
[1] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778
https://openaccess.thecvf.com/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
By:清华大学 王东