
第五篇 统计学习方法是如何实现分类与聚类的(十八)
清华大学计算机系 马少平
第十八节
特征抽取问题
小明:在讲统计机器学习方法的时候,我们常常用特征取值的向量表示样本,那么应该如何定义特征及其它们的取值呢?
艾博士:确实如小明所说的那样,在统计机器学习中,样本一般用特征取值的向量表示,我们称之为特征向量,请注意这里的特征向量与线性代数中特征向量的区别,二者说的不是一个意思。如何抽取特征也是统计机器学习中的关键问题,经常会听到这样的说法:如果特征选取得好的话,则用什么方法就显得不是那么重要了。这话虽然说的有些极端,不能说方法并不重要,但也确实反应了特征抽取的重要性。
小明:为什么特征抽取在统计机器学习中这么重要呢?
艾博士:我们人类在识别事物时具有很大的灵活性,可以很好地把握什么时候使用什么特征、什么时候需要组合哪些特征等问题。比如对于认识汉字来说,如何区别“清”和“请”?由于这两个字右边是完全一样的,区别只是在左边的偏旁不同,所以只需关注左边是什么偏旁就可以了。但是对于计算机来说这是个非常困难的事情,计算机如何知道右边是一样的?又如何知道偏旁是什么?让计算机分清楚“右边相同”、“左边偏旁不一样”这件事的难度并不比识别汉字更容易。所以抽取计算机更容易使用而且具有一定区分性的特征就成为了统计机器学习中重要的问题。这里的要点一是“计算机可以使用”,二是“具有一定的区分性”,缺一不可。
小明:我有些理解了,看起来特征抽取确实是非常重要。
艾博士:抽取什么样的特征与具体要解决的问题有关。下面我们分别通过两个例子说明如何实现特征抽取。
(1)文本分类问题
艾博士:比如我们想建立一个新闻网站,随时收集各种新闻报道。为了方便阅读,我们可以对新闻做分类,把类似内容的新闻放在一起。比如我们可以建立体育类、财经类、军事类和政治类四个类别,这样读者就可以选择自己感兴趣的新闻阅读。每来一篇新的新闻报道,系统就自动地将其分类到相应的类别中,这就是文本分类问题。
任何一种分类方法都可以用于文本分类,这里我们只说明如何抽取特征,构建表示每篇新闻的特征向量。
艾博士问小明:如果让你人工实现对新闻的分类,你会如何做呢?
小明:我首先阅读新闻,理解这篇新闻是讲什么的,然后根据其内容分类到相应的类别中。
艾博士:你这属于基于内容的分类,按理说让计算机实现分类也应该是首先理解新闻的内容再做分类。但是由于目前计算机还难于做到理解内容,只能通过使用的词汇判别新闻的类别。比如如果新闻中有比较多的用于描述体育比赛的词汇,则该新闻是体育类的概率比较大。所以我们可以以词汇作为分类的特征。
为此我们首先建立一个词表,这个词表可能会比较大,把新闻中所有可能用到的词基本都包括进来,可能要涉及几万甚至几十万个词汇。设词表长度,也就是词表包含的词汇数量为K,则最简单的方法是第i篇新闻用一个长度为K的向量Ti来表示,新闻中出现的词在向量的相应位置为1,否则为0。
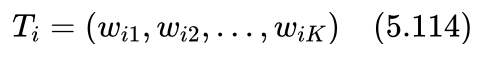
如果词表中第j个词汇出现在了训练集第i篇新闻中,则 wij 为1,否则为0。
这种方法只关注了一个词汇是否在新闻中出现,而没有考虑词汇出现的次数,显然词汇出现的次数对新闻所属的类别也是有影响的。
因此式(5.114)中的 wij 可以表示为词表中第j个词汇出现在训练集第i篇新闻中的数量。
单纯采用词汇出现的数量也存在问题,还需要考虑新闻的长度,在词汇出现数量相同的情况下,该词汇对于短新闻的作用应该大于对长新闻的作用。为了消除新闻长短对分类的影响,我们可以考虑用词频 tfij 代替式(5.114)中的 wij 。其中 tfij 表示词表中第j个词汇出现在第i篇新闻中的词频,即:

其中新闻的长度用新闻中包含的词汇数量表示。这样第i篇新闻就可以表示为:

这是一种基于词频的特征表示方法。
讲解到这里艾博士问小明:小明,你觉得这种词频表示法是否也存在不足呢?
小明思考了一会儿回答说:这种基于词频的特征表示方法,一个假设是新闻中出现的某个词汇数量越多,则这个词汇在分类中就越重要。但是有些词数量多确实对分类所起的作用大,比如乒乓球、足球等这些与体育紧密相关的词汇,新闻中包含的越多,其所属体育类的可能性就越大。但是有些没有明显的具体含义但是又经常被使用的词汇,可能在各个类别的新闻中都会经常出现,那么这样的词汇即便再多,对分类也起不到什么作用,比如“的”、“地”、“得”这些词汇,还有“我们”、“他们”等。
艾博士:小明说得非常正确,这样的词汇确实对分类起不到什么作用,还可能会起到反作用。
小明:那么是否可以把这些词汇删除掉呢?
艾博士:对词汇表做筛选确实是一种可行的方法,但是我们还是想探讨一些“自动”筛选词汇的方法。
比如说,我们可以引入这样的假设:一个词汇只在少数新闻中出现,则该词汇对分类的作用可能比较大,比如前面我们提到的“乒乓球”、“足球”等。如果一个词汇在很多新闻中都出现,极限情况下,几乎在所有新闻中都出现,则这样的词汇对分类的作用比较小,比如“的”、“地”、“得”等。
小明:引入这样的假设具有一定的合理性,但是如何在特征表示中体现出这一点呢?
艾博士:一种体现方式就是以词频为基础,对词频做加权处理。对于像“乒乓球”、“足球”这样的在少数新闻中出现的词汇,给予一个比较大的权重,而对于“的”、“地”、“得”这样的词汇,给予一个比较小的权重。这样就在一定程度上体现了不同词汇的重要程度。
小明:如何做到这一点呢?
艾博士:一种实现方法就是在训练集中统计每个词汇共出现在多少个新闻中,出现该词汇的新闻越多说明该词汇对分类的作用越小,出现的越少说明该词汇对分类的作用越大。也就是说,词汇的重要性与出现该词汇的新闻数成反比。为此我们定义词汇j的逆文档频率 idfj : 
上式分母中之所以要加1,是为了防止除以0的情况出现。这样,我们就可以用逆文档频率idfj 对词表中的第j个词汇的词频做加权。即式(5.114)中的 wij 为:
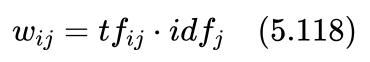
这样第i篇新闻就可以表示为:
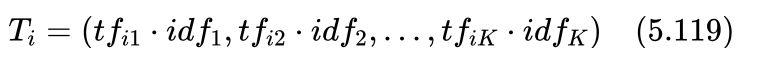
这种方法被称作tf-idf方法。
在实际使用时,tf-idf方法具有很多变形,常用的一种变形是对式(5.117)取对数,仍然叫做 :

tf-idf特征不仅仅用在文本分类中,很多文本处理任务也经常使用该特征,是统计机器学习中用的比较多的一种文本特征表示方法。
(2)脱机手写体汉字识别问题
艾博士:汉字识别就是让计算机认识汉字,这属于分类问题。手写体汉字识别分为两种情景,一种叫联机手写体汉字识别,也就是边写边识别,手机上的手写输入就是这种方式。这种方式的特点是计算机可以获取书写的笔画及顺序信息,识别起来相对容易一些。另一种方式叫脱机手写体汉字识别,这种方式是对手写在纸上的汉字,经扫描仪扫描后汉字作为图象传递给计算机做识别,由于可利用的信息少,识别起来难度也比较大。下面我们以脱机手写体汉字识别为例说明如何寻找合适的特征,如果没有特殊说明,后面所说的汉字识别均指脱机手写体汉字识别。
我们人认识汉字依靠的是偏旁部首、横竖撇捺等信息,可以认为是人采用的特征。但是这些特征对于计算机来说并不合适,因为提取偏旁部首、横竖撇捺等信息并不容易,其难度不亚于对汉字的识别。所以必须寻找既能区分不同汉字、计算机又可以自动处理的特征,才可以比较好地实现汉字识别。
汉字是由横竖撇捺等笔画构成的,不同的笔画、不同的位置,就构成了不同的汉字。我们虽然很难提取出这些笔画信息,但是如果能表示出在哪些地方具有“横竖撇捺”这些笔画元素,也可以把每个汉字的特征表达出来。这样就提出了一种用于脱机手写体汉字识别的方向线素特征,每个特征可以认为是一个反应笔画的“元素”,多个“元素”就表达出了一个汉字。
小明:听起来感觉是对的,具体如何实现呢?
艾博士:扫描的汉字图象是由像素组成的,假设每个笔画宽度都是单像素的,则在具有“横”笔画的位置,两个相邻像素间大多是左右关系,具有“竖”笔画的位置,两个相邻像素间大多是上下关系,而具有“撇”或者“捺”的位置,相邻像素间则大多是左下右上或者左上右下的关系。我们把这4种不同的像素关系称作元素,不同的元素反应了不同的笔画。如图5.61所示。
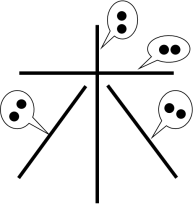
图5.61 汉字元素示意图
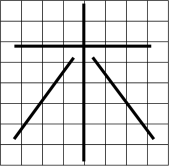
图5.62 汉字划分成8×8个区域示意图
我们将一个汉字均匀地划分成几个区域,比如说8×8共64个区域,如图5.62所示。分别统计不同区域内不同元素的数量,就可以反应出相应位置出现横竖撇捺的可能性,从而可以作为表示汉字的特征。这样一个汉字被划分为64个区域,每个区域有4个特征,一个汉字就可以用一个长度为256的特征向量表示了。
小明:手写汉字很不规范,笔画的位置也具有一定的随意性,比如“木”字的一横,写的靠上一些,就可能进入到上面的几个区域了,靠下一点的话,又可能进入到下面的几个区域,这种特征是不是稳定性并不好?
艾博士:小明说得很有道理。为此一般还要做些改进,尽可能减少书写随意性带来的影响。比如说,在划分区域时不是采用图5.62这种硬化分,而是采用软化分。也就是划分区域时,相邻的区域间具有一定的重叠覆盖,图5.63给出了一个中间区域采用软化分的示意图,其中虚线是硬化分的结果,而中间的实线框是软化分的结果,其区域扩大到了相邻的几个区域,在计算区域内的元素个数时,按照软化分的区域进行计算,并且软划分区域内不同位置的元素具有一定的加权,越是靠近中间位置权重越大,越是靠近边缘位置权重越小。这样就可以减小书写随意性带来的不良影响。根据这样的想法,定义方向线素所属区域的隶属度函数,就构成了模糊方向线素特征,这是我们在方向线素特征的基础上提出的一种改进方法。
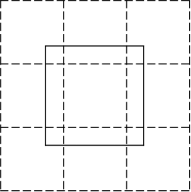
图5.63 软划分区域示意图
另外一般在抽取特征之前还要采用一些整形变换方法等对手写汉字图像做预处理,以便使得不同书写者书写的同一个汉字尽可能地一致。我们曾经提出过一种非线性整形变换方法,对汉字图像做预处理,图5.64给出了几个非线性整形变换的实例,其中图5.64(a)给出的是书写的原始汉字图像,从图中可以看出很不规整。图5.64(b)给出的是经非线性整形变换处理后的对应图像,从图中可以看出,预处理后的汉字图像显然规整多了,进一步减少了书写不规整带来的影响。

图5.64 非线性整形变换示意图
小明看着图5.64有些疑虑地问到:艾博士,您在介绍方向线素特征时,假定了笔画宽度是单像素的,但是从图5.64所展示的结果看,笔画宽度都比较宽,估计有3、4个像素宽,那么如何抽取方向线素特征呢?
艾博士:小明又提到了一个关键问题。经扫描得到的汉字图象,笔画宽度一般都比较宽,并不能直接抽取方向线素特征,需要先抽取汉字笔画的“骨架”,对笔画做细化处理,也就是将笔画宽度自动地处理成单像素宽度。但是细化处理并不是一件简单的事情,通常处理结果并不满意。为此我们采用汉字笔画的轮廓代替笔画“骨架”,对汉字笔画的轮廓抽取方向线素特征,而轮廓抽取相对来说要简单的多,这样就比较好地解决了脱机手写体汉字方向线素特征的抽取问题。图5.65给出了用笔画的轮廓代替笔画骨架的示意图。
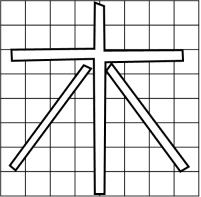
图5.65 笔画轮廓代替笔画骨架示意图
采用以上非线性整形变换方法以及模糊方向线素特征表示方法,并结合汉字识别的特点改进的统计机器学习方法,我们曾经成功地实现了大型中文古籍《四库全书》的识别,完成了《四库全书》的数字化。
小明:从您举的这个汉字识别的例子可以看出,解决实际问题是件复杂的事情,需要用到很多技术,综合实现才有可能比较好地解决实际问题。
艾博士:小明说得非常正确,我们这里只是介绍一些核心算法,必须同时结合很多“外围”技术才有可能解决好实际问题。
小明读书笔记
统计机器学习一般以特征作为输入,如何抽取特征在统计机器学习中起着举足轻重的作用。特征抽取与具体的任务有关,没有通用方法,本节以文本分类和脱机手写体汉字识别两个问题为例介绍了如何抽取特征问题。
对于文本分类任务,tf-idf是一种常用的特征。首先定义一个词典,第i篇文本表达为一个与词典长度相等的向量: 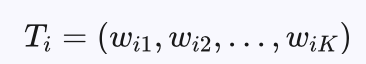
其中 wij 为词典中第j个词在第i个文本中的tf-idf特征:

常用的一种变形是:

对于脱机手写体汉字识别任务,方向线素是一种有效的特征。假设汉字的笔画宽度为一个像素,将一个汉字划分为8×8个区域,在每个区域内容数左右、上下、左上右下、右上左下排列的像素个数,一个区域用得到的4个数值表示,这样一个汉字就可以表示为8×8×4=256个元素的特征向量。
为了克服汉字笔画位移带来的不良影响,在划分区域时可以考虑相邻的区域具有一定的重叠,在对不同的像素个数计数时,按照其所在位置给予一定的加权,越靠近区域中间位置权重越大,越靠近区域边缘位置权重越小。基于这样的思想,定义每个方向像素所属区域的隶属度函数,就构成了模糊方向线素特征,一个汉字同样表示为长度为256的特征向量。
由于汉字图像笔画具有一定的宽度,而抽取笔画骨架的细化处理又有一定的难度,为此可以用笔画轮廓代替笔画骨架抽取特征。
未完待续