最近,AI生成技术引起热议。例如,我们向人工智能系统(例如,DALL-E)描述希望看到的景象,比如“在土星上穿着太空服的海豚”,系统可以生成出极具科幻感的图片。

图1. DALL-E 生成的“在土星上穿着太空服的海豚”
这些神奇图片的背后是一种称为扩散模型(diffusion model)的图像生成技术[1]。扩散大家都知道,往水里滴一滴墨水,过一会儿墨水就会在水中扩散开,分散到整个瓶子。扩散背后是墨水分子受水分子撞击,产生了随机运动。
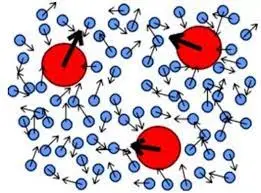

图2. 墨水扩散
人工智能领域中的扩散和物理学中的扩散有些类似。不同之处是,在人工智能中,扩散是指往原始图片中加入噪点,让图片越来越模糊,最后成了纯噪声。用于图片生成的扩散模型学习的是这一扩散过程的逆过程,即从一幅纯噪声图片开始一点点去掉噪声,使图像逐渐变得越来越清晰。
为了学习一个优秀的扩散模型,我们需要大量的图片数据进行训练,训练目标是逐渐从各种带噪图片中恢复出原始图片。为了达成这一目标,机器需要努力理解这些图片的特征和规律,从而获得图像生成的能力。
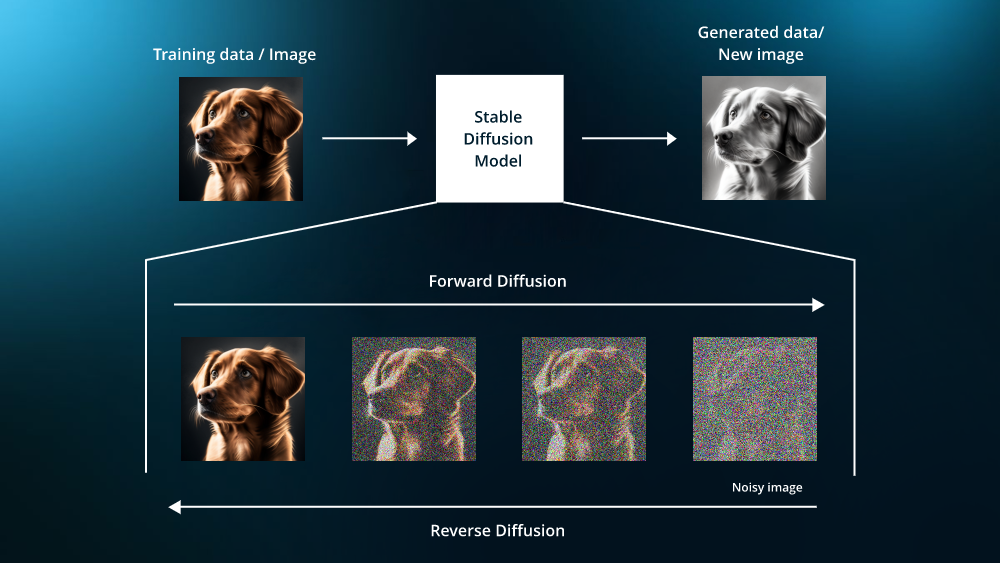
图3. 扩散模型示例
最后, 扩散模型生成的图片是随机的。为了让机器听懂人的生成指令,我们还需要一个语言理解模型。这个模型可以理解人的意图,并告诉扩散模型要生成什么样的图片。有趣的是, 一旦这一模型训练完成,它就放飞自我了,不仅可以生成“戴眼镜的小女孩”这种正常图片,还可以生成“穿着太空服的海豚”这种玄幻内容。
除了用于2D图像生成,扩散模型也被用于3D场景生成、图像去噪、视频生成[2]等领域,具有非常广泛的应用前景。
参考文献:
[1] Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[J]. Advances in neural information processing systems, 2020, 33: 6840-6851.
[2] https://github.com/ashawkey/stable-dreamfusion
By:利节、王东