显微镜是生物学家的利器,然而要得到高精度的显微成像并不容易。这是因为高精度成像需要昂贵的硬件且受实验条件限制,特别是对活体细胞、组织进行成像时,往往要求成像过程不能对原有的生物学特性产生影响,并且不能影响样本的健康状态。例如,在活体荧光成像中,就必须考虑光毒性的影响。
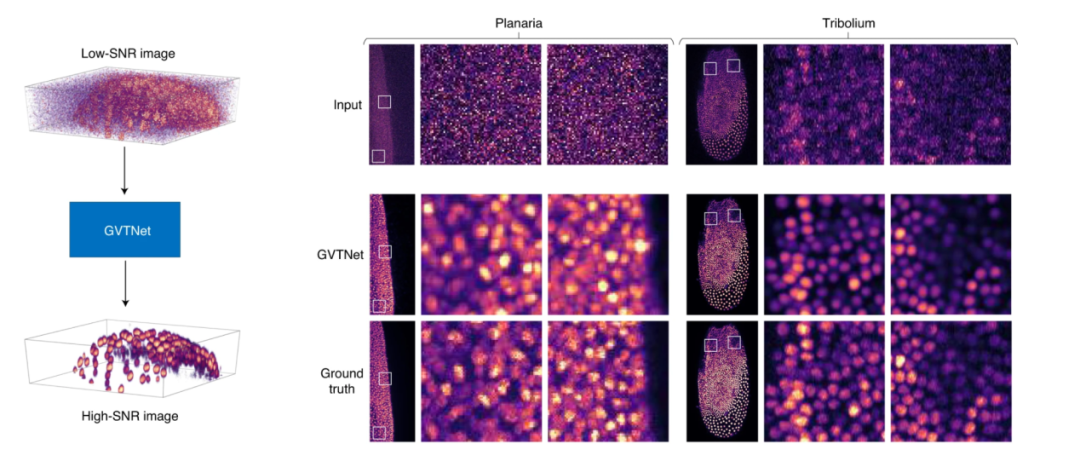
近日的自然-机器智能杂志发表了一篇来自美国德州农工大学的论文[1],报告了他们利用机器学习方法构造高清晰显微图像的成果。在文章中,他们设计了一个称为GVTNet的神经网络模型,将质量较低的显微图像输入该模型,即可在输出端得到高质量的显微图像,如图1所示。
图1:基于GVTNet的高清显微图像重构[1]。左图为系统示意图,右图为处理结果,其中第一行为输入的低质量图片,第二行为GVTNet模型生成的图片,第三行为原图[1]。
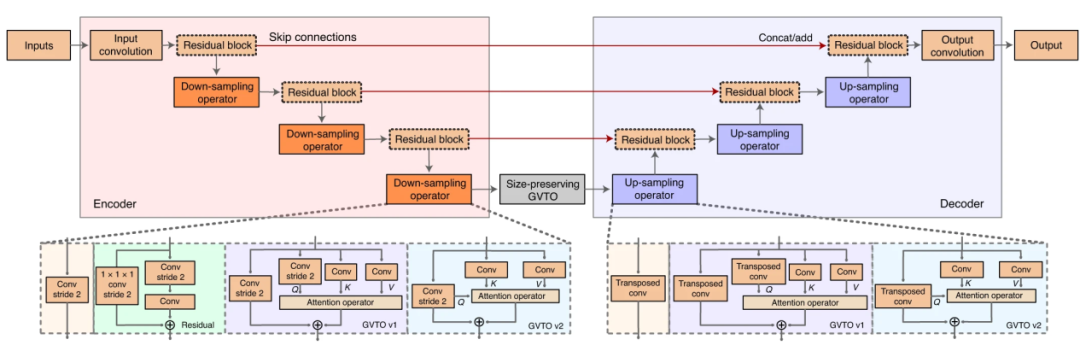
GVTNet的基本结构是一个U型编码-解码网络,如图2所示。输入的低质量图片经过编码网络生成图片内容的抽像表达,再由一个解码图络生成高质量图片。注意,在编码器和解码器的同等抽像层次上有直接连接,形成字母U的形状,因此称为U型网络。作者在该U型网络中引入了注意力机制,以提高对图片整体结构的学习能力。
GVTNet之所以可以由低质量图像生成高质量图像,主要原因在于深度神经网络可以有效学习高质量图像在高维空间中的分布形态,从而保证输出的图像是“真实”的。
图2:GVTNets结构示意图[1]。
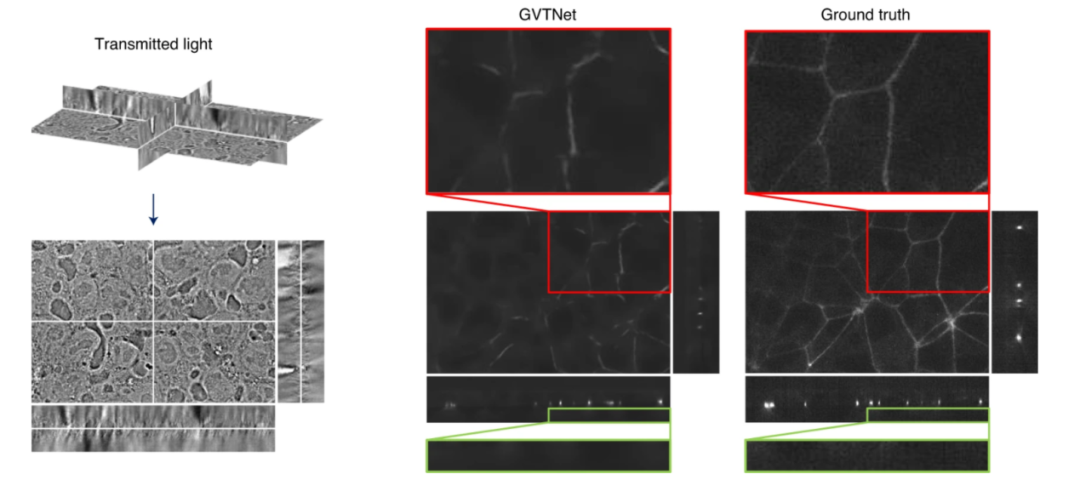
除了提高图片质量,GVTNet还可用于复杂显微图像的生成。例如,透射光显微成像(Transmitted-light Microscopy)是可以用较低成本得到的,而荧光显微图像(Fluorescence Imaging)则困难得多。将透射光图像和荧光显微图像分别作为输入和输出数据来训练GVTNet,基于该模型即可由透射光图像生成荧光显微图像,如图3所示。
图3:基于GVTNet由透射光图像生成荧光显微图像。左图为透射光图像,右图为GVTNet预测出的荧光显微图像及原始荧光显微图像[1]。
机器学习通过计算模型而不是物理设备实现了显微图像的增强,为生物学家提供了探索微观世界的新工具。然而,基于计算得到的显微图像不应该过度解读,因为这一方法强烈依赖输出端数据的先验分布,生成的图像可能与实际图像有所差异。例如,由低质量图片预测高质量图片的过程中,模型输出了更多细节,这些细节是模型基于先验概率“脑补”出来的,有可能不是真实的观测。
参考文献:
[1] Wang, Z., Xie, Y. & Ji, S. Global voxel transformer networks for augmented microscopy. Nat Mach Intell 3, 161–171 (2021). https://doi.org/10.1038/s42256-020-00283-x
By:清华大学 王东